Evaluating Small-Scale LLMs (up to 8B) on PT-BR Benchmarks
Background
This is the first of two posts in this series, aimed at providing a summary of the investigation we conducted using the HELM (Holistic Evaluation of Language Models) evaluation framework to assess the Granite family of models, the Llama-3.1-8B model, and the DeepSeek-R1-Distill-Llama-3.1-8B model. The evaluations cover both Portuguese-language benchmarks and code generation tasks. In this first part, the focus is on evaluating model performance in Brazilian Portuguese (PT-BR) for sentiment analysis and MQA (Multiple-Choice Question Answering) tasks. The second part, to be published soon, will present the evaluation results for code generation tasks.
The use of English-language datasets for evaluating language models is common practice. However, to evaluate this models across different languages and cultural contexts, it is important to test them on benchmarks in other languages. In the case of PT-BR, which typically represents a smaller share of the data used to train multilingual models, understanding model behavior is an important step in evaluating their suitability for tasks and contexts specific to this language. In this sense, this post aims to contribute to that understanding by highlighting both the advances and the remaining challenges in these LLMs’ performance on tasks in the PT-BR context.
TL;DR
- We evaluated the models: Granite, Llama-3.1-8B, and DeepSeek-R1-Distill-Llama-3.1-8B on the ENEM Challenge, TweetSent-Br, and IMDB benchmarks.
- Our method involved experimentation supported by the HELM framework, which we describe in detail in this document.
- The results show that the models accurately classify sentiments in movie reviews in PT-BR.
Method
Execution Environment and Tool Used
We used HELM as the evaluation tool. HELM is an LLM evaluation framework developed by researchers at Stanford University. It includes a variety of benchmarks, such as sentiment analysis, code generation, and multiple-choice question answering. Using these benchmarks, we evaluated and compared the performance of the Granite (8B), Llama-3.1-8B, and DeepSeek-R1-Distill-Llama-3.1-8B models.
For running the experiments, we used Google Colab as the environment, which provides access to an A100 GPU. In this setup, we were able to clone the HELM repository and run models with 8 billion parameters. All configuration and testing were carried out on this platform, ensuring convenience and access to the necessary computational resources.
In a future post, we will go into more detail about LLM evaluation strategies and tools, with a deeper focus on HELM’s capabilities and operation.
Benchmarks and Models
To run tests in Brazilian Portuguese scenarios, it was necessary to extend HELM by adding new benchmarks, since the tool did not previously support this language. This effort represented a direct contribution to HELM, adding three benchmarks:
ENEM Challenge: built from questions from the Exame Nacional do Ensino Médio (ENEM), designed to evaluate LLMs ability to handle MQA tasks across various knowledge areas, including Humanities, Natural Sciences, Languages, and Mathematics.
TweetSent-Br: composed of tweets, specifically for sentiment analysis tasks. The dataset is organized into three main classes: positive (tweets expressing a positive reaction about the main topic), negative (tweets expressing a negative reaction), and neutral (tweets that don’t fit the other categories).
IMDB: made up of movie reviews written in Brazilian Portuguese. This benchmark also focuses on sentiment classification tasks, but uses longer-form review texts, in contrast to TweetSent-Br’s shorter posts.
About the models, selection was guided by compatibility with the available execution environment and by citation relevance and performance. This included the Granite family of models developed by IBM; the Llama models from Meta; and the DeepSeek-R1-Distill-Llama-8B, a compact, optimized version derived from Llama 3.1. This choice enabled a fair and practical comparison among the models.
Results
Below, we present the results obtained, along with charts developed by the team to make it easier to visualize and understand the models’ performance on the evaluated tasks.
- ENEM Challenge:
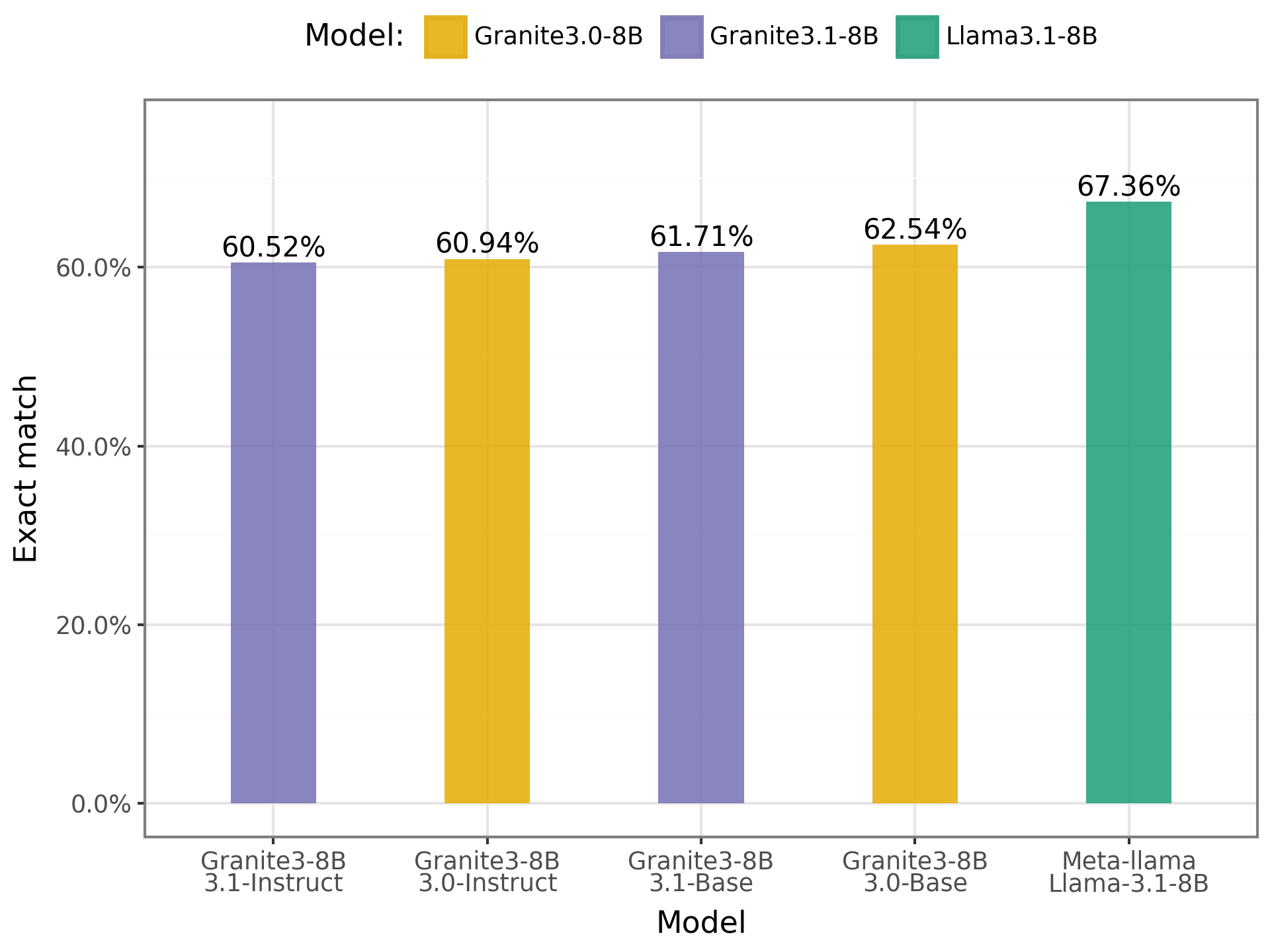
Chart of results on the ENEM Challenge
The results indicate that the models showed similar performance, with a slight advantage for Llama. The models achieved an average accuracy of 62.53%, suggesting that while they demonstrate some level of understanding of the questions, they still lack sufficient ability to answer ENEM exam questions satisfactorily. Improvement is still needed, particularly in reasoning and interpretation in Portuguese.
- TweetSent-Br:
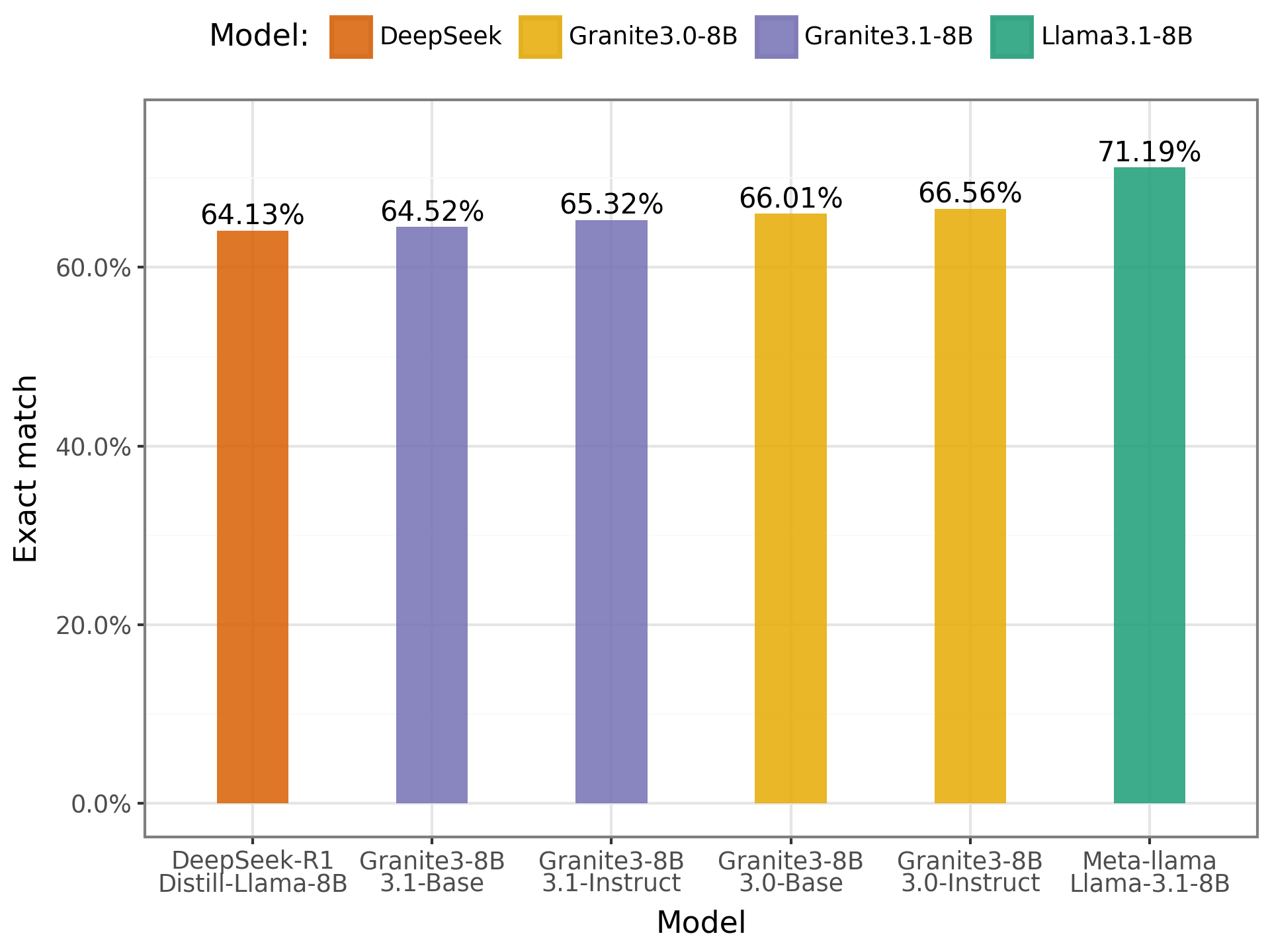
Chart of results on the TweetSent-Br
In this benchmark, as observed with the ENEM Challenge, the results were also similar across models. This reinforces the view that there are still gaps in model performance on sentiment classification tasks in Portuguese. Classifying a message as positive, negative, or neutral remains a challenge for these models, especially given the nuances and ambiguities of the language.
- IMDB:
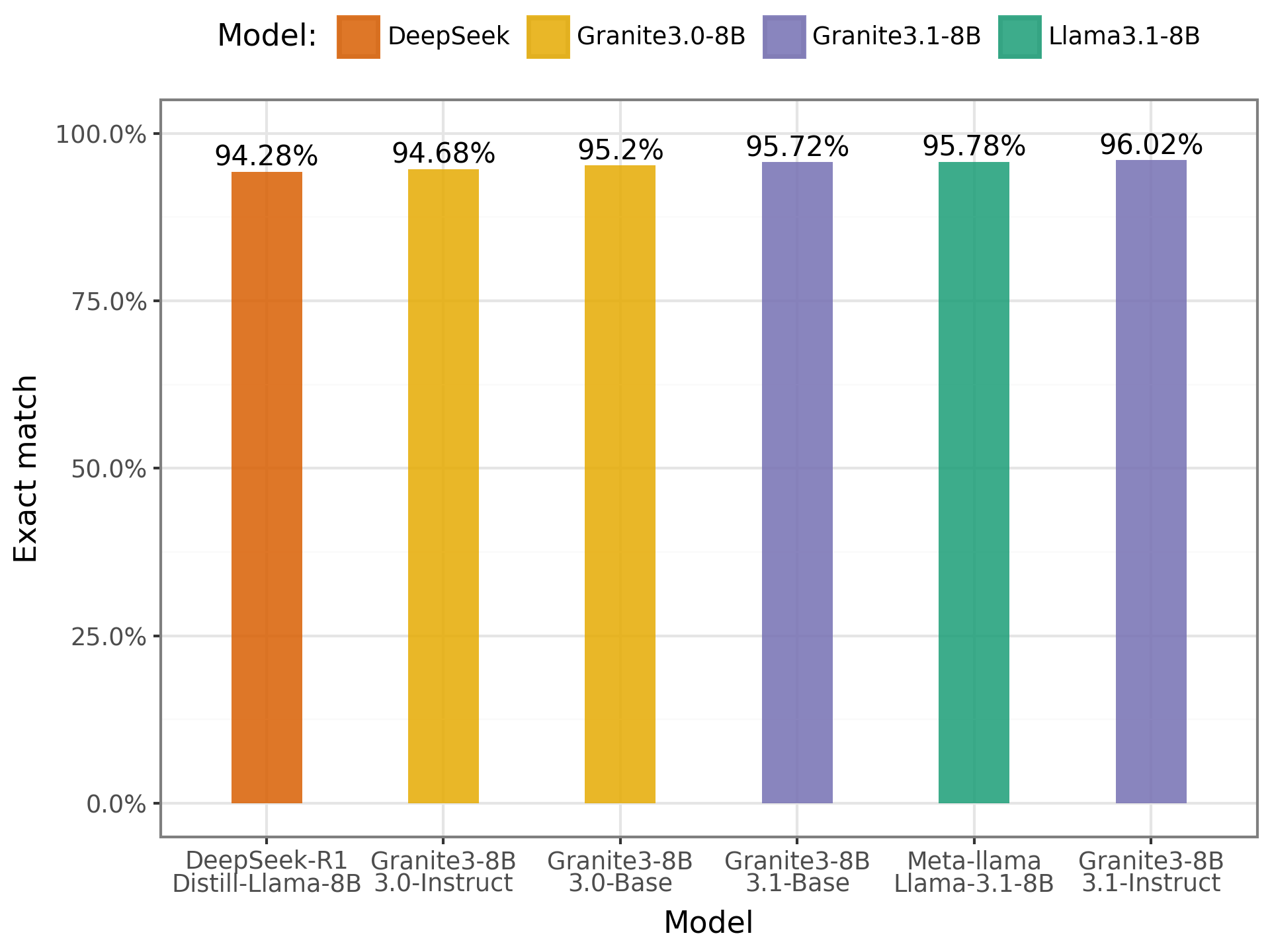
Chart of results on the IMDB
In the IMDB benchmark, the results were quite positive. The models achieved accuracy rates above 90%, demonstrating strong performance in sentiment classification. The highlight was the Granite model with 8B parameters, which showed a slight advantage over the others. These results indicate that the models can easily categorize movie reviews in Portuguese, showing greater proficiency in this type of task.
Conclusion
This study provided a clearer view of the performance of language models in PT-BR through evaluation on three different benchmarks. The results show that the models analyzed have reasonable performance when selecting an answer in ENEM knowledge areas, while also indicating that there is still room for improvement. On the other hand, in the IMDB sentiment analysis task, these smaller-scale models demonstrated good classification ability.
The team plans, in future studies, to conduct experiments with larger-scale models to enable broader comparisons of performance and efficiency. This will allow for a more detailed analysis of the errors made by each model, contributing to a deeper understanding of their strengths and limitations.