Evaluation of IBM Granite Models for Code-Generation Tasks on HumanEvalX
Context
The use of language models for code generation and understanding has become essential in modern development workflows.
As part of a joint research effort between LSD/UFCG and IBM, we investigated the performance of the IBM Granite 4 family on the HumanEvalX benchmark, which evaluates programming capabilities in five languages: Python, Java, Go, C++, and JavaScript.
The goal was to answer key questions from the team:
- How versatile are the Granite models across different languages?
- Do smaller models deliver useful performance?
- How do the Granites compare to models from other providers such as DeepSeek Coder and CodeLlama?
Methodology / Process
The evaluation was conducted using OpenCompass, a modern and extensible framework for large-scale LLM benchmarking. It allowed experiments to be executed in a standardized, reproducible way with consistent inference protocols.
Since OpenCompass does not provide native support for models hosted on the IBM Cloud, it was necessary to develop a custom client to integrate the framework with the IBM Cloud Inference API. This client allowed the evaluation process to send requests transparently, handle authentication, manage generation parameters, and return outputs in the expected benchmark format. Experiments were also run in Google Colab, which served as a practical environment for prototyping and running the models.
We used the HumanEvalX benchmark, an extension of the traditional HumanEval, covering five languages with the Pass@1 metric.
The evaluated models included:
- Granite 4.0 Micro (3B)
- Granite 4.0 (1B)
- Granite 4.0 h-tiny (7B)
- Granite 4.0 h-small (30B) — via IBM Cloud
- granite 4.0 (350M)
- granite code instruct 8B — via IBM Cloud
- DeepSeek Coder (6.7B)
- CodeLlama (7B)
The metric used was Pass@1, following the benchmark protocol.
Results and Conclusions
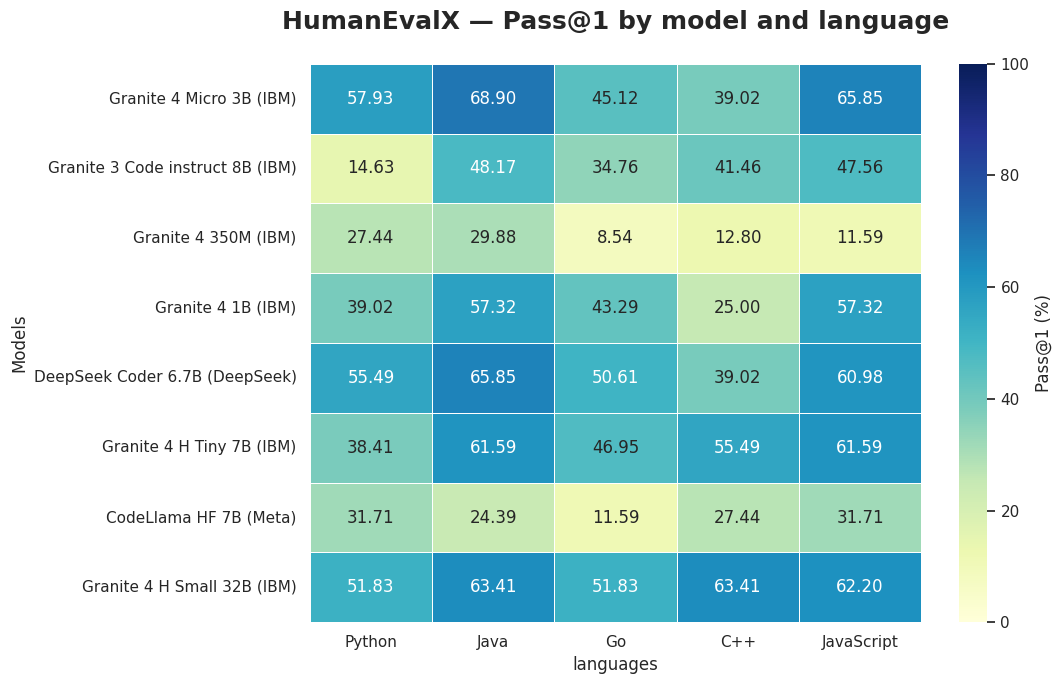
Performance heatmap of the models on HumanEvalX.
The evaluation revealed important behaviors:
1. granite-4.0-h-small stood out for its versatility
He surpassed 60% Pass@1 in Java, C++, and JavaScript, while also maintaining over 50% in Python and Go. This consistent performance across languages suggests that the model has good generalization capability, showing promise in scenarios that involve different programming ecosystems, although additional benchmarks and evaluations are important before drawing broader conclusions.
2. Granite Micro (3B) performed above expectations
Despite being a small model, Granite Micro (3B) delivered 65.85% in JavaScript and 68.90% in Java, outperforming even some larger models evaluated. This shows that even with a compact architecture, it can deliver solid results, making it a highly efficient option for applications that require low computational cost without sacrificing performance.
3. The size progression (350M → 1B → 3B → 7B → 30B) shows gradual and coherent evolution
The results show that as we move through the different sizes of the Granite line, there is a coherent evolution in performance. Smaller models deliver stable results within their category, while larger ones gradually expand the ability to solve more complex tasks. This distribution helps clarify where each model fits in the usage spectrum.
4. Comparing different providers helps contextualize the results
Alongside the IBM models, we also evaluated models from other providers such as DeepSeek and Meta. In some languages, the differences were small, but in all of them there was at least one model from the Granite family that achieved the highest score. The Granite 4 Micro (3B) and Granite 4 h-small (30B) models were the standouts, with results that were close to, and in some cases above, those of models recognized as code specialists.
Next Steps
- Run the same Granite models on LiveCodeBench, a broader benchmark that goes beyond code generation, also evaluating code execution and test-output.
- Perform a fine-tuning of the Granite 4.0 Micro (3B) using InstructLab and observe the impact of this adaptation on the model’s performance in HumanEvalX, comparing before and after the adjustment.