Avaliando LLMs de Pequeno Porte (até 8B) em Benchmarks PT-BR
Contexto
Este é o primeiro de dois posts desta série, que tem como objetivo apresentar um resumo da investigação que conduzimos utilizando o framework de avaliação HELM (Holistic Evaluation of Language Models) para avaliar os modelos da família Granite, o modelo Llama-3.1-8B e o modelo DeepSeek-R1-Distill-Llama-3.1-8B. As avaliações contemplam tanto benchmarks em português quanto tarefas voltadas à geração de código. Nesta primeira parte, o foco é avaliar o desempenho dos modelos no contexto do português brasileiro (PT-BR) para as tarefas de análise de sentimentos e MQA (Multiple-Choice Question Answering). Depois, na segunda parte, que será publicada em breve, abordará os resultados das avaliações em tarefas de geração de código.
O uso de conjuntos de dados em inglês para a avaliação de modelos de linguagem é uma prática comum. No entanto, para verificar a eficácia desses modelos em diferentes idiomas e contextos culturais, é relevante testá-los em benchmarks de outras línguas. No caso do PT-BR, que costuma representar uma parcela menor dos dados utilizados no treinamento de modelos multilíngues, compreender o comportamento desses modelos é um passo importante para avaliar sua adequação a tarefas e contextos específicos dessa língua. Neste sentido, este post busca contribuir para esse entendimento, destacando avanços e desafios ainda presentes no desempenho dessas LLMs em tarefas no contexto do PT-BR.
TL;DR
- Avaliamos os modelos: Granite, Llama-3.1-8B e DeepSeek-R1-Distill-Llama-3.1-8B nos benchmarks ENEM Challenge, TweetSent-Br e IMDB.
- Nosso método envolveu uma experimentação apoiada pelo framework HELM, que apresentamos em detalhes neste documento.
- Os resultados revelam que os modelos classificam com precisão os sentimentos em críticas de filmes em PT-BR.
Método
Ambiente de Execução e Ferramenta Utilizada
O HELM foi a ferramenta utilizada para conduzir as avaliações. Trata-se de um framework de avaliação de LLMs, desenvolvido por pesquisadores da Universidade de Stanford, que contempla uma variedade de benchmarks, como análise de sentimentos, geração de código, questões de múltipla escolha, entre outros. Com base nesses benchmarks, utilizamos os modelos Granite (até 8B), Llama-3.1-8B e DeepSeek-R1-Distill-Llama-3.1-8B para medir e comparar seus desempenhos.
Para a execução dos experimentos, utilizamos o Google Colab como ambiente, que conta com uma GPU A100. Neste ambiente, foi possível clonar o repositório do HELM e executar modelos com até 8 bilhões de parâmetros. Todo o processo de configuração e testes foi realizado nessa plataforma, garantindo praticidade e acesso aos recursos computacionais necessários.
Em uma postagem futura, iremos detalhar as estratégias e ferramentas de avaliação de LLMs, com um foco mais aprofundado no funcionamento e nas capacidades do HELM.
Benchmarks e Modelos
Para realizar os testes em cenários voltados ao português brasileiro, foi necessário estender o HELM com a inserção de novos benchmarks, uma vez que, até então, a ferramenta não apresentava suporte para esse idioma. Essa iniciativa representou uma contribuição direta ao HELM, com a adição de três benchmarks:
ENEM Challenge: construído a partir de questões do Exame Nacional do Ensino Médio (ENEM), com o objetivo de avaliar a capacidade dos LLMs em resolver tarefas de MQA em diversas áreas do conhecimento, incluindo Ciências Humanas, Ciências da Natureza, Linguagens e Códigos e Matemática.
TweetSent-Br: composto por tweets, voltado especificamente para tarefas de análise de sentimentos. O dataset é organizado em três classes principais de avaliação: positivo (tweets que expressam uma reação ou avaliação positiva em relação ao tópico principal da postagem), negativo (tweets que expressam uma reação ou avaliação negativa sobre o tema central) e neutro (tweets que não se enquadram nas categorias anteriores).
IMDB: composto por críticas de filmes escritas em português brasileiro, esse benchmark também se concentra em tarefas de classificação de sentimentos, mas utiliza textos originados de resenhas mais completas, ao contrário do TweetSent-Br, que usa publicações breves.
Em relação aos modelos, a seleção foi guiada pela compatibilidade com a infraestrutura de execução disponível e com base na relevância de citações e performance. Estes incluem os modelos da família Granite, desenvolvidos pela IBM; os modelos Llama, da Meta; e o DeepSeek-R1-Distill-Llama-8B, uma versão compacta e otimizada derivada do Llama 3.1. Essa escolha permitiu uma comparação justa e viável entre os modelos.
Resultados
A seguir, apresentamos os resultados obtidos, acompanhados de gráficos desenvolvidos pela equipe, com o objetivo de facilitar a visualização e compreensão do desempenho dos modelos nas tarefas avaliadas.
- ENEM Challenge:
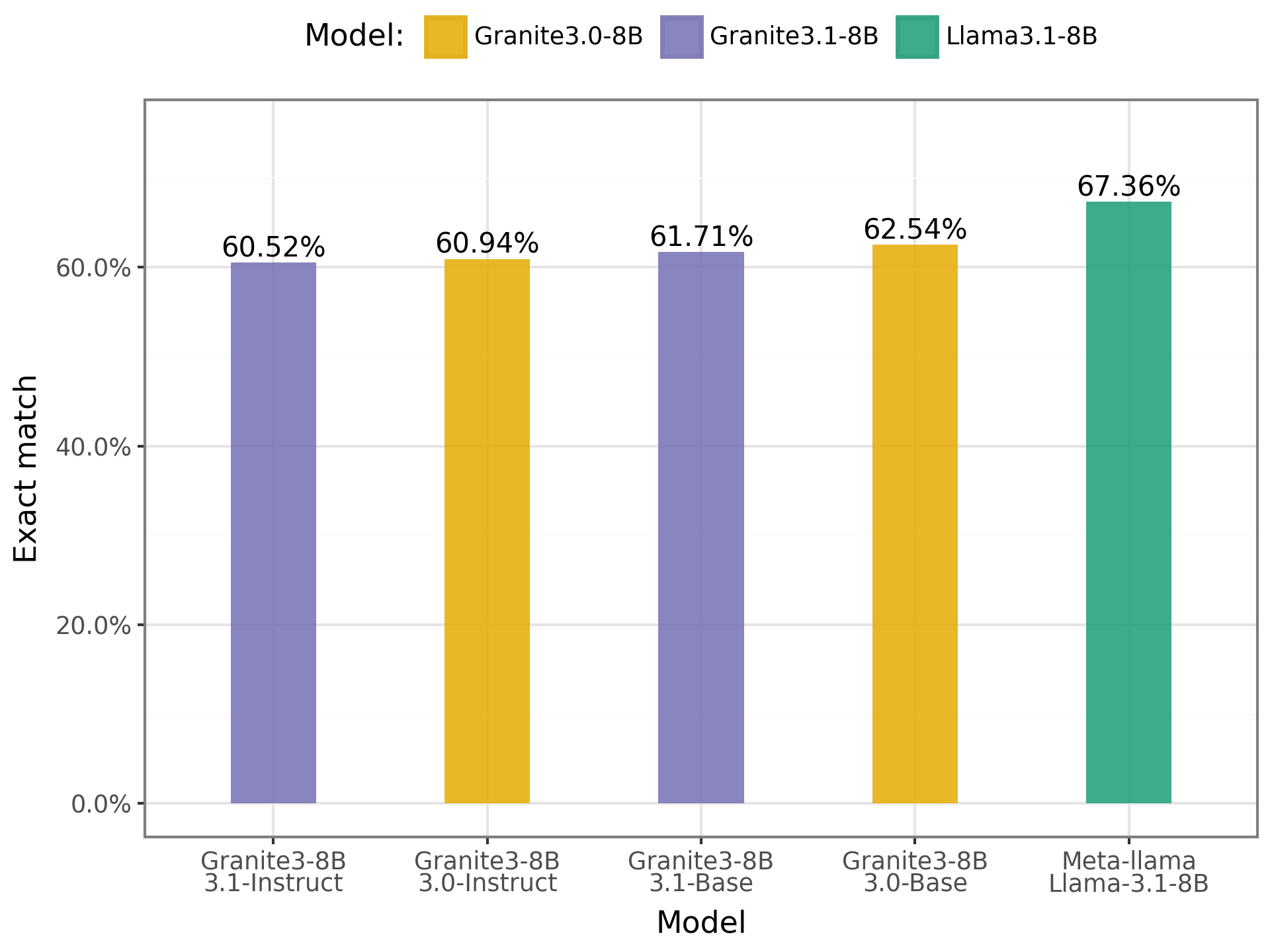
Gráfico dos resultados no ENEM Challenge
Os resultados indicam que os modelos apresentaram desempenhos semelhantes, com uma leve vantagem para o Llama. Os modelos alcançaram uma média de acerto de 62,53%, esse percentual sugere que, embora os modelos demonstrem algum nível de compreensão das questões, ainda não possuem aptidão suficiente para responder de forma satisfatória às provas do ENEM, ou seja, para selecionar a alternativa correta. Há, portanto, um espaço para melhorias, especialmente no que diz respeito à capacidade de raciocínio e interpretação em língua portuguesa.
- TweetSent-Br:
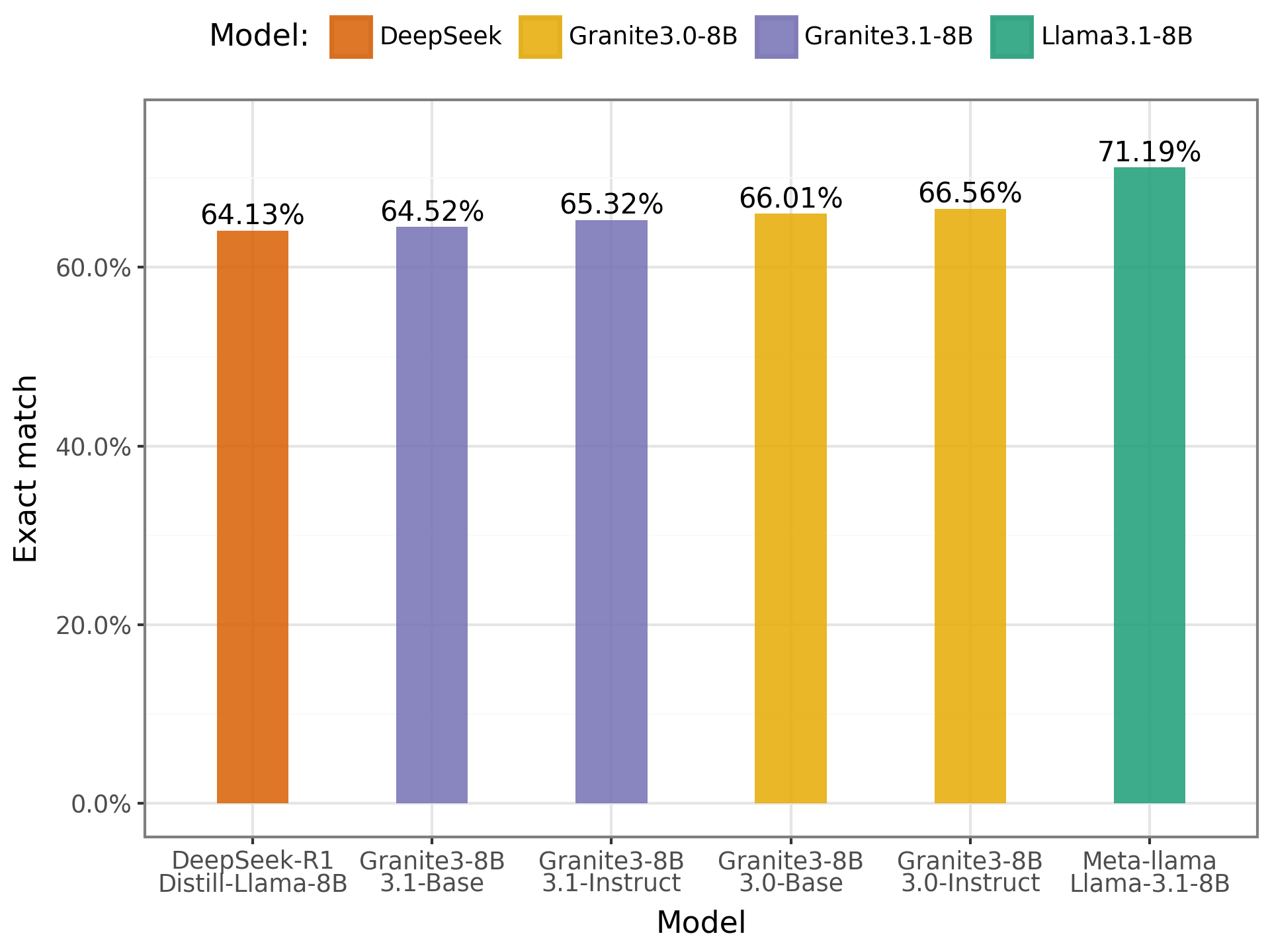
Gráfico dos resultados no TweetSent-Br
Nesse benchmark, assim como observado no ENEM Challenge, os resultados também foram semelhantes entre os modelos. Isso reforça a percepção de que ainda existem lacunas no desempenho dos modelos em tarefas relacionadas à classificação de sentimentos em português. Classificar uma mensagem como positiva, negativa ou neutra ainda representa um desafio para esses modelos, especialmente diante das nuances e ambiguidades da linguagem.
- IMDB:
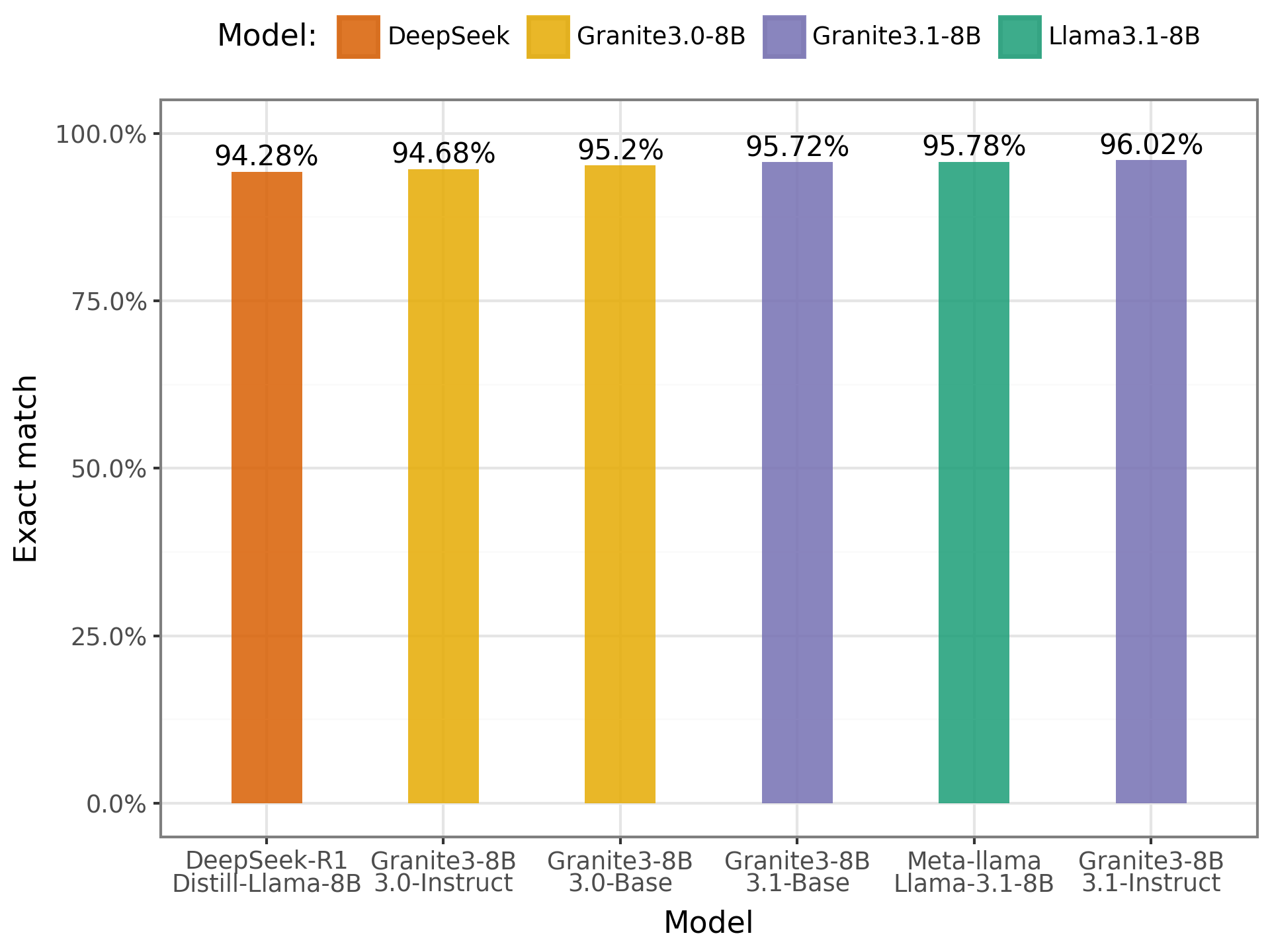
Gráfico dos resultados no IMDB
No IMDB os resultados foram bastante positivos, os modelos apresentaram taxas de acerto superiores a 90%, demonstrando boa performance na tarefa de classificação de sentimentos. O destaque foi o modelo Granite com 8B de parâmetros, que teve uma leve superioridade em relação aos demais. Esses resultados indicam que os modelos conseguem categorizar com facilidade as críticas de filmes em português, mostrando maior domínio nesse tipo de tarefa.
Conclusão
Com este estudo, foi possível obter uma visão mais clara sobre o desempenho dos modelos de linguagem em PT-BR, por meio da avaliação em três benchmarks distintos. Os resultados indicam que os modelos analisados possuem desempenho razoável ao selecionar uma alternativa para áreas do conhecimento do ENEM, e evidenciam que ainda há espaço para melhorias. Por outro lado, em tarefas de análise de sentimentos no benchmark IMDB, os modelos de pequeno porte demonstraram boa capacidade de classificação.
A equipe planeja, em estudos futuros, conduzir experimentos com modelos de grande porte, a fim de possibilitar comparações mais amplas de desempenho e eficiência. Isso permitirá uma análise detalhada dos erros cometidos por cada modelo, contribuindo para uma compreensão mais aprofundada de seus pontos fortes e limitações.