Contaminação por dados de Benchmark em LLMs: Fundamentos, Causas e Estratégias de Detecção
Contexto
Benchmarks são estruturas organizadas e padronizadas que podem ser utilizadas para avaliar o desempenho de grandes modelos de linguagem (LLMs). Compostos, em geral, por uma base de dados, um conjunto de tarefas e métricas de avaliação, esses recursos fornecem um ponto de referência comum para mensurar avanços, comparar arquiteturas e orientar decisões de desenvolvimento e implantação.
Apesar de seu uso recorrente, os resultados obtidos em benchmarks podem ser influenciados por diversos fatores. Um dos fatores ocorre quando, de alguma forma, os dados de teste são previamente expostos ao modelo durante seu treinamento. Esse cenário caracteriza o fenômeno conhecido como contaminação por dados de benchmark, que pode ocorrer de forma acidental ou deliberada. A presença desse tipo de contaminação tende a comprometer a avaliação, pois o modelo pode memorizar parcial ou integralmente os exemplos avaliados em uma determinada tarefa, distorcendo seu desempenho real.
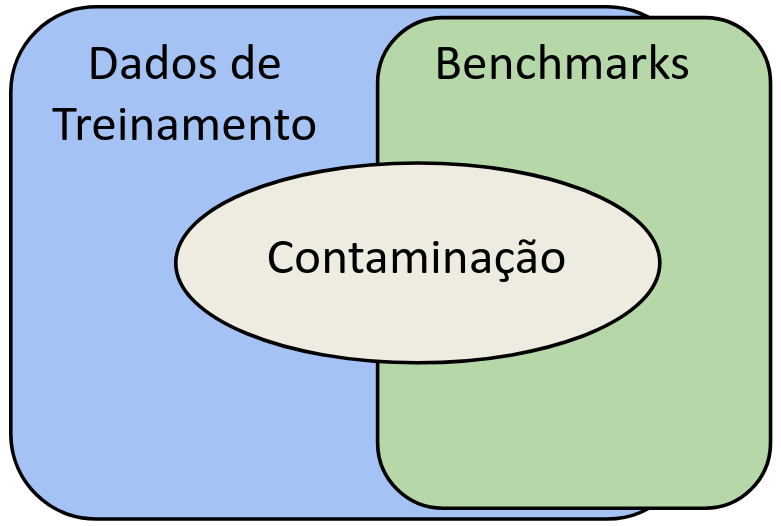
Contaminação por dados de benchmark
Com o objetivo de introduzir e difundir esse tema, esta postagem apresenta os fundamentos conceituais da contaminação por dados de benchmark, suas causas recorrentes e as metodologias atualmente utilizadas para sua detecção.
TL;DR
- Modelos são vulneráveis à contaminação quando os dados utilizados para testá-lo são previamente expostos durante o treinamento.
- A contaminação pode ocorrer de forma acidental ou intencional e compromete a validade das avaliações.
- Existem diferentes formas de contaminação, que variam pelo conteúdo exposto, momento da exposição e nível de abstração.
- Métodos de detecção podem ser diretos (quando os dados de treinamento são acessíveis) ou indiretos (baseados em comportamento ou inferência).
- Ferramentas como LLMSanitize, BenBench, ConStat e CDD-TED auxiliam na identificação sistemática de contaminações.
Impactos da contaminação
A contaminação por dados de benchmarks provoca distorções que afetam tanto o rigor científico das avaliações quanto a confiabilidade de aplicações baseadas em LLMs. Os principais impactos descritos abaixo, também são discutidos em estudos como [1] [5] [7].

Riscos da contaminação por dados de benchmark
Inflacionamento de métricas: A exposição prévia aos dados de avaliação pode elevar artificialmente o desempenho dos modelos, resultando em métricas superestimadas, como acurácia e calibragem. Isso dificulta a interpretação precisa de suas capacidades reais.
Avaliação comprometida: Quando um benchmark é aplicado a modelos que já tiveram acesso a seus dados, ele deixa de refletir a dificuldade real das tarefas, comprometendo sua função como instrumento de avaliação imparcial.
Redução da generalização: A contaminação favorece a memorização de exemplos específicos em vez da aprendizagem de padrões gerais, o que reduz a capacidade do modelo de lidar com dados não vistos, especialmente em casos de contaminação por rótulo ou semântica.
Riscos em aplicações sensíveis: Avaliações contaminadas podem levar à adoção de modelos em domínios críticos, como saúde, direito e finanças, com base em métricas distorcidas. Isso aumenta o risco de falhas operacionais e decisões inadequadas.
Comparações enviesadas e desperdício de recursos: A contaminação prejudica a equidade entre modelos, especialmente quando apenas alguns foram expostos previamente aos dados de benchmark. Isso compromete comparações, favorece modelos não auditáveis e pode levar à alocação ineficiente de recursos.
Comprometimento da integridade científica: Avaliações baseadas em benchmarks contaminados afetam a reprodutibilidade e podem resultar em conclusões inválidas, enfraquecendo a confiabilidade de estudos que utilizam esses resultados como base empírica.
Causas da contaminação por dados de benchmark
A contaminação por dados de benchmarks em LLMs pode ocorrer de forma acidental [1] [4] ou intencional [1] [3], com diferentes origens e consequências, dependendo principalmente da forma como os dados de treinamento são coletados, utilizados e reaproveitados nos ciclos de desenvolvimento dos modelos.
A contaminação acidental é a mais comum e ocorre, na maioria dos casos, devido ao uso de dados extraídos automaticamente da internet para pré-treinamento em larga escala [1] [4]. Esses corpora, por sua diversidade e volume, frequentemente incluem conteúdos associados a benchmarks, como exemplos idênticos, trechos brutos ou textos semanticamente relacionados. Isso se deve ao fato de benchmarks e dados de treinamento frequentemente compartilharem fontes públicas comuns, como Wikipedia, repositórios educacionais, artigos técnicos e redes sociais.
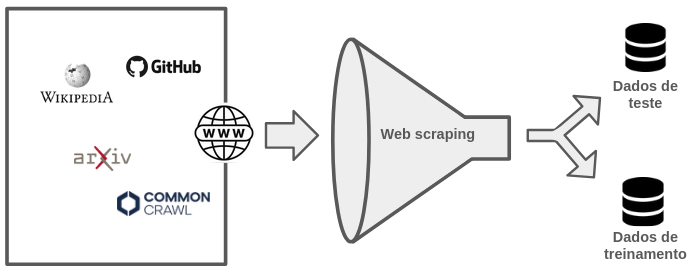
Exemplo de fluxo de contaminação não intencional
Embora mecanismos de filtragem possam ser implementados para evitar a inclusão de benchmarks conhecidos, essa estratégia apresenta limitações [4]. É difícil garantir a exclusão de todos os benchmarks existentes, especialmente os lançados recentemente ou ainda não amplamente documentados. Além disso, a identificação de sobreposição semântica é complexa, o que torna a detecção de vazamentos indiretos ainda mais desafiadora.
Outro vetor de contaminação acidental está relacionado à reutilização de interações com usuários para re-treinamento ou ajuste fino de modelos implantados em produção [7]. Sistemas comerciais podem reaproveitar entradas fornecidas por usuários durante testes, avaliações públicas ou uso real. Quando essas interações reproduzem exemplos derivados de benchmarks, há risco de contaminação retroativa, mesmo que não intencional, nos ciclos seguintes de treinamento.
Além disso, a contaminação pode se propagar por meio da geração de conteúdo por LLMs [1]. Modelos contaminados podem gerar textos que replicam padrões ou trechos presentes em benchmarks, mesmo que de forma parafraseada ou reestruturada. Esses textos, quando reutilizados em novos benchmarks ou conjuntos de treinamento, perpetuam e amplificam a contaminação original. Apesar de, nesses casos, os desenvolvedores poderem estar cientes da contaminação prévia, a natureza recursiva do processo faz com que a propagação ocorra de forma indireta e, muitas vezes, incontrolável. Por esse motivo, esse tipo de exposição também pode ser considerado um caso de contaminação acidental.
Por outro lado, a contaminação intencional ocorre quando dados de benchmark são deliberadamente incluídos no treinamento, com o objetivo de melhorar o desempenho do modelo em tarefas específicas [1] [3]. Essa prática pode ocorrer, por exemplo, ao incorporar conjuntos como MATH ou GSM8K com o propósito de otimizar a performance em raciocínio matemático [6]. Embora esse uso possa ser justificável como dado supervisionado, sua posterior reutilização como benchmark invalida a avaliação.
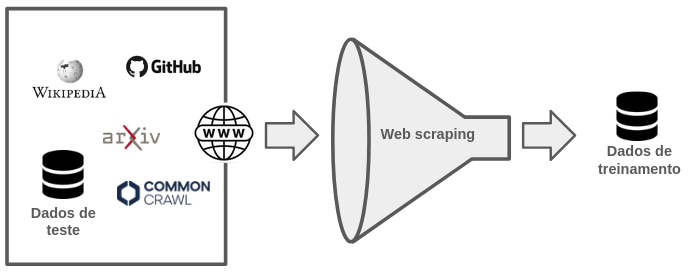
Exemplo de fluxo de contaminação intencional
É fundamental que, em casos como esse, haja transparência na documentação dos modelos. benchmarks utilizados como parte do treinamento não devem ser reaplicados como instrumentos de avaliação. Ainda assim, essa distinção nem sempre é respeitada, especialmente em modelos comerciais cuja documentação é limitada ou inexistente [5].
Categorias e níveis de contaminação
A contaminação por dados de benchmark pode assumir diferentes formas, variando conforme o tipo de conteúdo exposto, o grau de abstração da informação vazada e o estágio do treinamento em que a contaminação ocorre. Essas categorias não são mutuamente exclusivas e frequentemente se combinam, o que torna o fenômeno difícil de rastrear e mitigar.
Em muitos casos, a exposição ocorre devido a um vazamento de entrada, que é quando apenas as entradas dos benchmarks são expostas ao modelo [4], como perguntas, comandos ou prompts. No entanto, há situações em que tanto as entradas quanto os rótulos ou respostas anotadas estão presentes no treinamento, e essa situação é conhecida como vazamento de entrada-saída [4].
Outra forma comum de categorizar a contaminação é quando os modelos são expostos ao texto bruto utilizado na construção de benchmarks [5], como artigos da Wikipedia, decisões judiciais ou descrições técnicas. Complementarmente, há o caso que envolve a contaminação por diretrizes de anotação [5], quando o modelo acessa instruções empregadas no processo de rotulagem dos dados. Esse tipo de vazamento pode induzir comportamentos compatíveis com os critérios esperados pelo benchmark, mesmo sem exposição direta aos exemplos.
Além disso, a contaminação pode ocorrer em diferentes níveis de abstração. No nível semântico, o modelo é exposto a conteúdos conceitualmente semelhantes ou derivados dos benchmarks, como reformulações, tópicos correlatos ou textos provenientes da mesma fonte [1]. Essa forma de vazamento pode introduzir vieses temáticos e comprometer a capacidade de generalização do modelo, sendo difícil de detectar por não envolver cópia literal. No nível informacional, o vazamento ocorre por meio de estruturas secundárias associadas ao benchmark, como distribuições temporais, frequências de rótulos, metadados ou até análises externas sobre o conjunto de dados [1]. Essas informações, mesmo sem conter o conteúdo principal, podem influenciar sutilmente o comportamento do modelo. No nível de dados, ocorre a exposição literal de exemplos do conjunto de avaliação, mas sem os rótulos correspondentes, o que ainda assim permite que o modelo aprenda padrões específicos do benchmark [1]. Já no nível de rótulos, o caso mais crítico, tanto os exemplos quanto os rótulos estão presentes no treinamento, o que favorece memorização direta, reduz a capacidade de generalização e compromete seriamente a validade da avaliação [1].
Por fim, a contaminação pode ocorrer em diferentes fases do ciclo de treinamento [5]. Durante o pré-treinamento, é comum que corpora amplos e não curados incluam trechos relacionados a benchmarks, por compartilharem fontes comuns. No ajuste fino supervisionado, conjuntos rotulados podem conter instâncias próximas ou idênticas às utilizadas posteriormente nos dados de teste do modelo. Já na fase pós-implantação, dados derivados de interações com usuários ou gerados por outras LLMs também podem introduzir contaminação, especialmente quando reaproveitados para re-treinamento.
Essas diferentes manifestações evidenciam que a contaminação por dados de benchmarks é um fenômeno multifacetado, que pode ser sutil ou direta, intencional ou não, com impactos relevantes para a validade das avaliações, a comparação entre modelos e a confiabilidade dos sistemas desenvolvidos.
Metodologias de detecção
A identificação de contaminação em benchmarks exige metodologias específicas, que variam conforme o nível de acesso ao modelo avaliado. Esse acesso costuma ser classificado em três categorias. Modelos caixa branca permitem acesso completo aos pesos e aos dados de treinamento. Modelos caixa cinza têm documentação limitada e expõem distribuições de probabilidade ou valores de log‑probabilidade, mas não os dados originais. Já modelos caixa preta oferecem apenas as respostas finais, sem qualquer visibilidade sobre arquitetura ou treinamento.
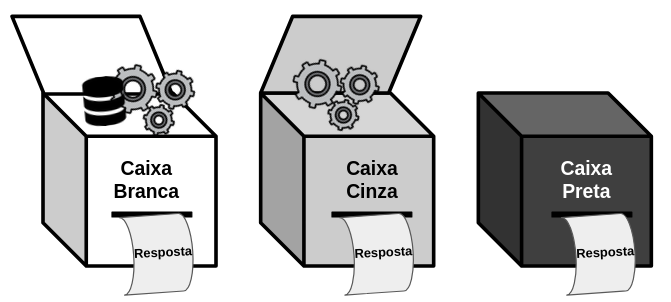
Níveis de acesso a modelos
Cada configuração impõe limitações próprias e condiciona as técnicas de detecção disponíveis. Metodologias de detecção direta, como busca por duplicação literal ou análise de similaridade semântica, requerem transparência total sobre os dados de treinamento e, portanto, aplicam‑se principalmente a modelos caixa branca [1] [3] [4]. Já metodologias de detecção indireta, focadas em vazamentos comportamentais, manipulação de entrada, perturbações ou evidências temporais, podem ser empregadas inclusive em modelos caixa cinza ou caixa preta, pois não dependem de acesso direto aos dados utilizados no treinamento [3] [4]. A seguir, apresentam‑se as principais abordagens descritas na literatura, organizadas de acordo com a origem da evidência e o grau de inferência envolvido.
Metodologias de detecção direta
Algumas metodologias de detecção partem da premissa de que o conjunto de dados utilizado no treinamento do modelo é conhecido ou publicamente acessível. Nesses casos, é possível realizar comparações diretas entre os dados de teste (benchmarks) e os dados efetivamente utilizados no treinamento, o que permite evidenciar contaminações com alto grau de precisão.
Modelos classificados como caixa branca, como o Tucano, disponibilizam não apenas a arquitetura e os pesos, mas também todo o processo de pré-processamento e os dados utilizados no treinamento, possibilitando esse tipo de verificação. Já para modelos caixa cinza, mesmo entre os de código aberto como o LLaMA ou o Mistral, a ausência dos dados de treinamento impossibilita a aplicação dessas estratégias.
Entre os métodos mais utilizados nesse cenário estão:
String matching: busca por duplicações exatas entre exemplos do benchmark e entradas do conjunto de treinamento. Essa técnica utiliza substrings, n‑gramas ou trechos completos, sendo eficiente e de fácil implementação. Embora direta e objetiva, há limitação quanto à identificação de repetições literais, sem capturar variantes semânticas ou paráfrases [4].
Similaridade via embeddings: utiliza representações vetoriais de sentenças para medir a proximidade semântica entre exemplos do conjunto de treinamento e do benchmark. Essa técnica permite identificar contaminações menos explícitas, como reformulações e variações estruturais, sendo especialmente útil em casos em que não há duplicações literais. No entanto, além de mais custosa, sua eficácia depende da escolha apropriada do modelo de embeddings e da métrica de distância utilizada [4].
Detecção de paráfrases: utiliza LLMs ou classificadores especializados para avaliar se exemplos do benchmark são paráfrases de conteúdos previamente vistos. Essa abordagem é útil quando há suspeita de reformulações, mas exige supervisão humana ou limiares bem definidos para reduzir falsos positivos [4].
Essas técnicas são consideradas concretas e verificáveis, pois operam diretamente sobre os dados de treinamento e permitem mensurar de forma clara a sobreposição com os benchmarks. No entanto, apresentam alto custo metodológico, já que requerem acesso completo aos dados de treinamento e demandam recursos computacionais significativos para análise em larga escala.
Metodologias de detecção indireta
Em contextos em que os dados de treinamento não são públicos, como no caso de modelos proprietários (GPT-4, Claude ou Gemini), não é possível realizar comparações diretas com os benchmarks. Nessas situações, a detecção de contaminação depende de evidências indiretas, geralmente obtidas por meio de inferência estatística, análise cronológica ou observação de comportamentos em tarefas específicas.
Essas abordagens são especialmente relevantes em modelos classificados como caixa preta e caixa cinza, nos quais não há acesso aos dados de treinamento. Ainda assim, também podem ser aplicadas a modelos caixa branca, especialmente em análises comparativas, complementares ou em cenários de validação cruzada.
As principais estratégias empregadas nesse cenário incluem:
Análise cronológica: busca comparar o desempenho do modelo em benchmarks publicados em momentos distintos. Uma melhora abrupta em benchmarks liberados após a data de corte do treinamento pode sugerir exposição posterior ao conteúdo de teste [4].
Análise comportamental: avalia se o modelo responde corretamente a variações nos exemplos do benchmark, como prompts truncados, reordenados ou parafraseados. Técnicas como o TS-Guessing exploram esse princípio para detectar memorização implícita [2] [4].
Inferência por confiança: abrange métodos que estimam a presença de exemplos de treinamento com base no padrão de respostas do modelo. Técnicas como os Membership Inference Attacks (MIA) e o BenBench comparam o grau de confiança ou perplexidade do modelo em exemplos suspeitos em relação a exemplos sabidamente fora do treinamento. Uma concentração anormal de confiança ou variação de perplexidade em itens específicos pode indicar memorização [4] [6].
Essas metodologias são úteis para detectar contaminação em modelos sem transparência sobre seus dados de origem, mas envolvem maior grau de incerteza. Por dependerem de inferências comportamentais ou contextuais, os resultados exigem interpretação cuidadosa, especialmente quando utilizados de forma isolada. Ainda assim, úteis para a avaliação de modelos comerciais ou sem documentação disponível.
Ferramentas auxiliares na detecção de contaminação
Com o aumento da preocupação em torno da contaminação por dados de benchmarks, diversas ferramentas têm sido desenvolvidas para automatizar e padronizar estratégias de detecção. Essas ferramentas integram métodos complementares baseados em correspondência literal, similaridade semântica, comportamento do modelo e análises estatísticas, permitindo investigações mais robustas mesmo em contextos com acesso restrito aos dados ou aos parâmetros dos modelos.
O LLMSanitize implementa diversas técnicas descritas em diferentes estudos, oferecendo métodos voltados a modelos caixa branca, como string matching, truncamento de entrada e avaliação semântica com LLMs, bem como estratégias para modelos caixa cinza e caixa preta, como o TS-Guessing e o Sharded Likelihood, metodologias baseadas em análise comportamental.
Algumas ferramentas são voltadas a metodologias específicas. O BenBench, por exemplo, busca sinais de memorização implícita por meio da análise de perplexidade, similaridade e acurácia em versões originais e parafraseadas de benchmarks, sendo especialmente útil na avaliação de modelos caixa preta ou caixa cinza. O ConStat é voltado à comparação estatística entre o desempenho do modelo em dados suspeitos e em outros benchmarks similares, visando detectar padrões de desempenho atípicos. Já o CDD-TED propõe o uso de benchmarks diagnósticos controlados para examinar discrepâncias na distribuição de confiança e entropia das respostas, oferecendo evidências indiretas de contaminação.
Essas ferramentas representam meios práticos e sistemáticos para detectar exposições em diferentes níveis.
Conclusão
A contaminação por dados de benchmark constitui um desafio relevante para a avaliação justa de modelos de linguagem. Como discutido ao longo do texto, esse fenômeno compromete a validade das métricas, dificulta comparações entre LLMs e pode levar à adoção de modelos com desempenho superestimado em aplicações reais.
Para mitigar a contaminação, diversas estratégias têm sido indicadas na literatura. Entre elas, destacam-se a reformulação de benchmarks por meio de técnicas como paraphrasing e back-translation, a criação de conjuntos de teste dinâmicos, o uso de avaliações mediadas por modelos de linguagem mais robustos e a implementação de benchmarks privados com acesso controlado. No entanto, essas soluções ainda enfrentam limitações práticas, especialmente em idiomas sub-representados, nos quais a variedade e a qualidade dos dados disponíveis são restritas.
Este artigo apresentou uma caracterização geral da contaminação por dados de benchmark, abordando suas causas, impactos e principais metodologias de detecção. Como continuidade, serão conduzidos estudos empíricos com foco em idiomas sub-representados. Embora a maioria dos trabalhos existentes se concentre em idiomas amplamente representados nos dados globais, como o inglês e o chinês, há indícios de que o problema seja ainda mais crítico em línguas com menor presença nos repositórios de treinamento. A escassez de benchmarks exclusivos e a ampla reutilização de fontes públicas aumentam a probabilidade de sobreposição entre dados de treinamento e teste nesse contexto.
Tomando o português brasileiro como exemplo de idioma sub-representado, os estudos futuros utilizarão modelos multilíngues e especializados no idioma, com o objetivo de estimar o grau de exposição a dados de avaliação e contribuir para práticas mais consistentes de validação e comparação entre modelos.
Referências
[1] Cheng Xu, Shuhao Guan, Derek Greene, and M-Tahar Kechadi. 2024. Benchmark Data Contamination of Large Language Models: A Survey. arXiv preprint arXiv:2406.04244.
[2] Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. 2024. Investigating Data Contamination in Modern Benchmarks for Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8706–8719, Mexico City, Mexico. Association for Computational Linguistics.
[3] Chunyuan Deng, Yilun Zhao, Yuzhao Heng, Yitong Li, Jiannan Cao, Xiangru Tang, and Arman Cohan. 2024. Unveiling the Spectrum of Data Contamination in Language Model: A Survey from Detection to Remediation. In Findings of the Association for Computational Linguistics: ACL 2024, pages 16078–16092, Bangkok, Thailand. Association for Computational Linguistics.
[4] Mathieu Ravaut, Bosheng Ding, Fangkai Jiao, Hailin Chen, Xingxuan Li, Ruochen Zhao, Chengwei Qin, Caiming Xiong, and Shafiq Joty. 2024. How much are LLMs contaminated? A Comprehensive Survey and the LLMSanitize Library. arXiv preprint arXiv:2404.00699.
[5] Oscar Sainz, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. 2023. NLP Evaluation in Trouble: On the Need to Measure LLM Data Contamination for Each Benchmark. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Singapore. Association for Computational Linguistics.
[6] Ruijie Xu, Zengzhi Wang, Run-Ze Fan, and Pengfei Liu. 2024. Benchmarking Benchmark Leakage in Large Language Models. arXiv preprint arXiv:2404.18824.
[7] Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondrej Dusek. 2024. Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 67–93, St. Julian’s, Malta. Association for Computational Linguistics.