Inferência de LLMs com Ollama na IBM Power9 Utilizando CPU
Contexto
Este post apresenta um guia prático para realizar inferência de grandes Modelos de Linguagem (LLMs) utilizando o Ollama, em um ambiente IBM POWER9. O Ollama é um framework baseado no llama.cpp, projetado para simplificar a implementação e execução de tais modelos, oferecendo uma interface amigável e suporte para diversas tarefas.
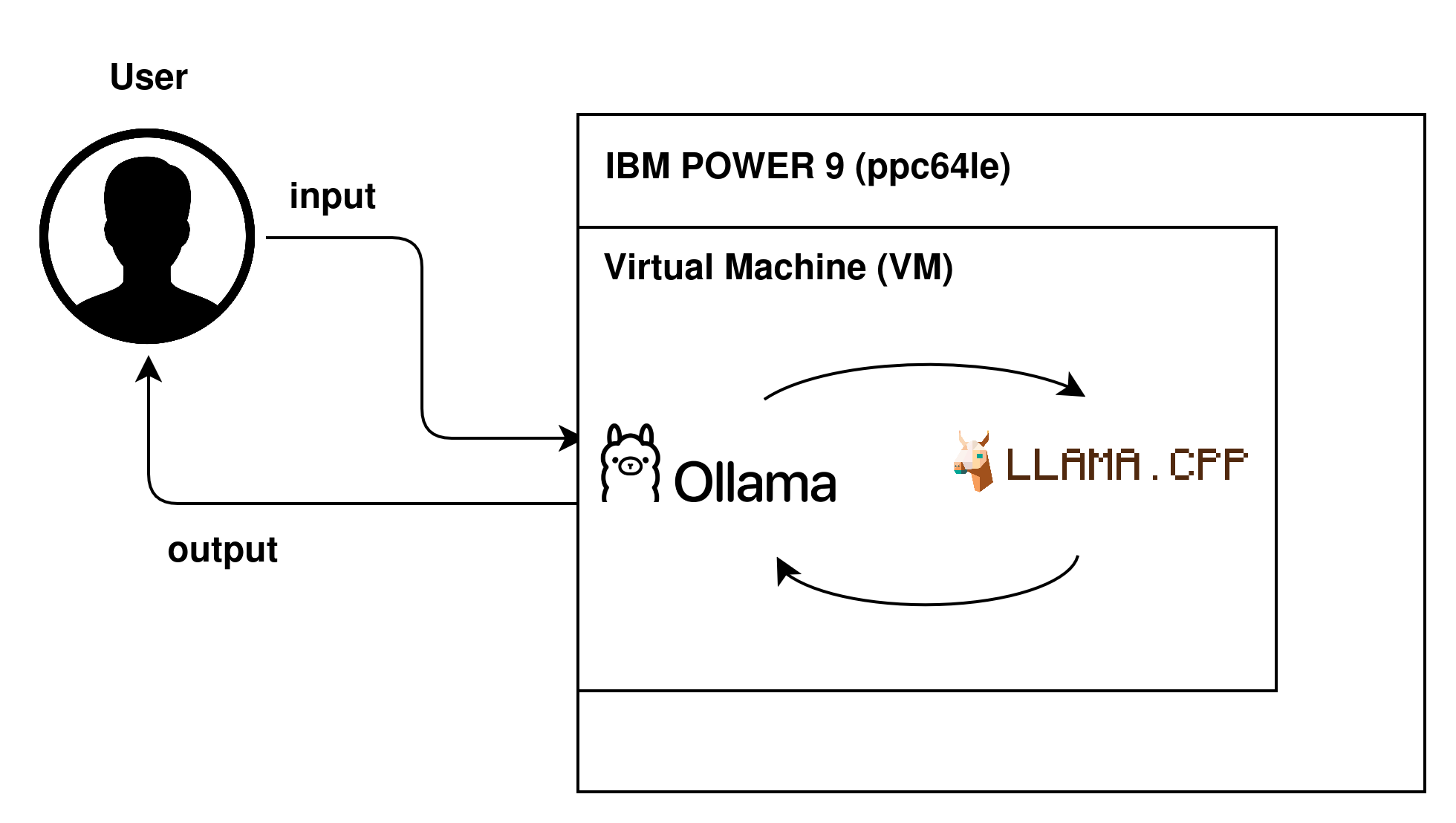
Fluxo de uma requisição
Apesar do crescimento no uso de LLMs, a disponibilidade de materiais voltados para a arquitetura ppc64le (IBM POWER9) ainda é bastante limitada. Em geral, os tutoriais disponíveis são antigos, pouco detalhados ou focados em arquiteturas mais comuns, como x86_64, o que dificulta a reprodução do ambiente no contexto apresentado. Este é o primeiro de dois posts dessa série, que tem como objetivo realizar a inferência inteiramente via CPU, explorando a arquitetura ppc64le, de maneira atualizada, prática e reproduzível. No próximo post, abordaremos a utilização de GPU para acelerar o processo.
TL;DR
- Este post apresenta detalhes sobre como configurar o ambiente para realizar inferências com a infraestrutura da IBM POWER9.
- A execução é realizada via CPU utilizando o Ollama;
- O principal desafio envolve a configuração correta do ambiente, especialmente dependências como Go, GCC e CMake, além da compatibilidade com RHEL
Ambiente utilizado
Hardware:
- Arquitetura ppc64le;
- RAM: ~64GB;
- Execução: Máquina Virtual (VM);
Sistema Operacional: Alma Linux 8.10 (ppc64le), binário compatível com Red Hat Enterprise Linux (RHEL) 8.9/8.10.
Setup inicial
Para executar o Ollama na arquitetura POWER9, é necessário preparar o ambiente com as dependências adequadas. O primeiro passo é atualizar o sistema e instalar os utilitários básicos:
sudo dnf update -y
sudo dnf install -y wget git tar make gcc gcc-c++ cmake gcc-toolset-11
Embora esse comando instale parte das dependências, é necessário garantir que as versões corretas estejam sendo utilizadas.
Configuração do Go
O Ollama é desenvolvido em Go, portanto é necessário garantir a versão adequada.
Versão esperada: 1.25.7 linux/ppc64le
Caso não esteja instalado:
wget https://go.dev/dl/go1.25.7.linux-ppc64le.tar.gz
sudo tar -C /usr/local -xzf go1.25.7.linux-ppc64le.tar.gz
export PATH=/usr/local/go/bin:$PATH
Para adicionar ao PATH permanentemente:
echo 'export PATH=/usr/local/go/bin:$PATH' >> ~/.bashrc
source ~/.bashrc
Verifique se a versão está correta: go version
Configuração do Cmake
Verifique se a versão está correta: cmake --version
Versão esperada: cmake 3.26.5
Caso não esteja instalado:
wget https://github.com/Kitware/CMake/releases/download/v3.26.5/cmake-3.26.5.tar.gz
tar -xzf cmake-3.26.5.tar.gz
cd cmake-3.26.5
./bootstrap
make -j$(nproc)
sudo make install
Configuração do GCC
Versão esperada: gcc 11.2.1
Importante: No AlmaLinux 8, o gcc-toolset não é ativado automaticamente. É necessário habilitar a sessão manualmente:
scl enable gcc-toolset-11 bash
Esse comando ativa o GCC apenas na sessão atual. Se abrir outro terminal, será necessário executar o comando novamente.
Verifique a versão: gcc --version
Caso não esteja instalado:
sudo dnf install -y gcc-toolset-11
scl enable gcc-toolset-11 bash
Clonando o Ollama
Com o ambiente configurado, podemos realizar o build do Ollama. Aqui vamos clonar o repositório oficial do ollama e mudar a versão utilizada (importante para a compatibilidade com a POWER e para obter uma versão estável).
cd /root
git clone https://github.com/ollama/ollama.git
cd ollama
#Alterar a versão:
git checkout v0.9.4
Para verificar, use: git status
Build do Ollama
Após ativar GCC na versão certa:
export CGO_ENABLED=1
go clean -cache -modcache -i -r
go build -o ollama .
O CGO precisa estar habilitado porque o Ollama depende do llama.cpp, que utiliza código em C/C++ para otimizações de performance. Sem isso, o build falha ou perde compatibilidade com a arquitetura.
Isso deve ocorrer sem nenhum erro e gerar o binário ollama criado no diretório atual.
Para verificar: ./ollama --version
Realizando a Inferência
Com o Ollama compilado, podemos iniciar o servidor:
./ollama serve
Uma observação importante é que, como o ambiente está sendo executado em uma máquina virtual, não é possível manter o comando em execução no terminal principal e, simultaneamente, utilizar outro terminal na mesma sessão para realizar a inferência, sem alguma ferramenta auxiliar para gerenciar múltiplos terminais. O que faremos então é executar o servidor em segundo plano (background), mas você pode optar por usar Tmux ou Screen, permitindo que o mesmo terminal continue disponível para a execução dos demais comandos (que veremos a seguir). Para isso, você pode rodar:
./ollama serve &
Para verificar se deu certo: ps aux | grep ollama. Vai aparecer algo assim:

Ollama executando
Baixar o modelo de teste e executar a inferência
Para validação, utilizamos o modelo TinyLlama, por ser leve e adequado para execução em CPU. Para isso, em outro terminal, rode:
./ollama pull tinyllama
Para executar a inferência:
./ollama run tinyllama "O céu é azul?"
Se tudo tiver sido feito de maneira correta, você terá algo como:

Inferencia sendo executada
É importante destacar que o Ollama trabalha, por padrão, com modelos disponibilizados em seu próprio repositório, que já estão convertidos e otimizados para execução, geralmente no formato compatível com o llama.cpp. Esses modelos podem ser facilmente utilizados por meio do comando ollama pull, como no caso do TinyLlama utilizado neste exemplo. Embora seja possível utilizar modelos externos, isso exige etapas adicionais, como a conversão para formatos compatíveis (por exemplo, GGUF) e a criação de um Modelfile.
Considerações Finais
Com os passos apresentados, foi possível configurar o ambiente para executar inferências de LLMs em uma máquina IBM POWER9 utilizando a CPU. Apesar de ser funcional, essa abordagem apresenta limitações no desempenho, especialmente para modelos maiores, devido a ausência de aceleração via GPU. Como próximo passo, pretendemos explorar a execução utilizando GPU, avaliando ganhos de desempenho e escalabilidade.
Próximos Passos
- Testar versões mais recentes e a compatibilidade entre elas;
- Realizar uma experimentação de benchmarks para comparar o desempenho da Inferência em CPU em relação a inferência em GPU;
- Segundo post dessa série, realizando inferência em GPU.