Inferência de LLMs com Ollama na IBM Power9 Utilizando GPU
Contexto
Este é o segundo post da série sobre inferência de modelos de linguagem na POWER9 com o Ollama. Neste post, abordaremos como enviar requisições utilizando GPU, obtendo um ganho significativo de desempenho em relação à abordagem via CPU apresentada no post anterior.
O principal desafio é que o Ollama não oferece suporte oficial para a arquitetura ppc64le com CUDA. A solução encontrada foi através de um blog da comunidade oficial IBM, onde um contribuidor disponibilizou um fork do Ollama adaptado para suportar GPUs NVIDIA na POWER9 via CUDA. No entanto, esse fork está desatualizado e não suporta modelos mais recentes como Gemma 3 e DeepSeek.
Por isso, desenvolvemos um fork atualizado, baseado no Ollama oficial (v0.23.2), com os patches necessários para ppc64le e suporte a GPU via CUDA. Este tutorial explica como compilar o Ollama para a arquitetura ppc64le, e para quem não quiser compilar, também disponibilizamos um binário pré-compilado nas releases no GitHub.
TL;DR
- Este post apresenta detalhes sobre a configuração do ambiente para realizar inferências utilizando a infraestrutura da IBM POWER9;
- O Ollama não oferece suporte oficial para ppc64le com CUDA;
- O fork foi compilado do zero utilizando CMake e Go, apontando para CUDA 12.2 e especificando a arquitetura do V100 (
sm_70); - Um binário pré-compilado também está disponível no github do projeto;
- Com isso, foi possível executar inferência de LLMs na IBM POWER9 com aceleração GPU e suporte para modelos recentes.
Ambiente utilizado
Hardware:
- Arquitetura ppc64le;
- RAM: mínimo recomendado de ~64GB;
- GPU: NVIDIA Tesla V100;
- Driver NVIDIA: 535.54.03;
- CUDA: versão 12.2.
Sistema Operacional: Alma Linux 8.10 (ppc64le), binário compatível com Red Hat Enterprise Linux (RHEL) 8.9/8.10.
Verificações iniciais
- Verificar se o driver e a GPU estão visíveis
nvidia-smi
- Verificar se o CUDA está instalado
nvcc --version
OBS: Se não aparecer nada, tente:
export PATH=/usr/local/cuda-12.2/bin:$PATH
export CUDACXX=/usr/local/cuda-12.2/bin/nvcc
- Verifique também se o CUDA 12 existe:
ls -la /usr/local/cuda-12
Execução em Ambiente Virtual
Neste tutorial, estamos fazendo as configurações necessárias em um ambiente virtual para isolar o ambiente de execução e as configurações utilizadas. Essa execução é opcional, mas recomendada.
conda create -n ollamaGPU python=3.11 -y
conda activate ollamaGPU
Para desativar o ambiente:
conda deactivate
Setup inicial
Para compilar o Ollama na POWER9, são necessárias as seguintes dependências com as versões adequadas:
- Go: 1.26.0
- GCC: 11.2.1 (via gcc-toolset-11)
- CMake: >= 3.24
Clonando e compilando o Ollama
Com o ambiente configurado, podemos realizar o build do Ollama. A compilação utiliza CMake para gerar os kernels CUDA com nvcc, e Go para compilar o binário. Um detalhe importante é o parâmetro CUDA_ARCHITECTURES=70: cada GPU NVIDIA possui uma arquitetura específica identificada por um código sm_XX, e o V100 é da arquitetura Volta (sm_70). Especificando esse valor, instruímos o build a compilar apenas para o V100, reduzindo o tempo de compilação.
O passo a passo completo de compilação, incluindo os fixes necessários para ppc64le, além da instalação e configuração das dependências mencionadas anteriormente, está documentado no README do repositório.
Para quem não quiser compilar, um binário pré-compilado está disponível diretamente na página de releases:
# Baixe o binário
wget https://github.com/llm-pt-ibm/ollama-ppc64le/releases/download/v0.23.2-ppc64le-power9/ollama-ppc64le
# Dê permissão de execução
chmod +x ollama-ppc64le
Nota: O repositório contém as branches do Ollama oficial. Os patches para ppc64le estão exclusivamente na branch ollama-ppc64le.
Realizando a inferência
Com o Ollama compilado, podemos iniciar o servidor:
./ollama serve
Para verificar se deu certo, digite o comando: ps aux | grep ollama.
Aguarde alguns segundos e verifique os logs para confirmar que o servidor detectou as GPUs corretamente. Procure por estas linhas:
inference compute ... library=CUDA compute=7.0 ... description="Tesla V100-SXM2-16GB" total="16.0 GiB"
Baixar o modelo de teste e executar a inferência
Para validação, utilizamos o modelo llama3.1:8b. Para isso, em outro terminal, rode:
./ollama pull llama3.1:8b
Para executar a inferência:
./ollama run llama3.1:8b "me fale todos os números ímpares até 100"
Confirmar o uso da GPU
Em outro terminal, com a inferência em execução, rode:
nvidia-smi
Na seção de processos, você deve ver o ollama com memória alocada em uma das GPUs:
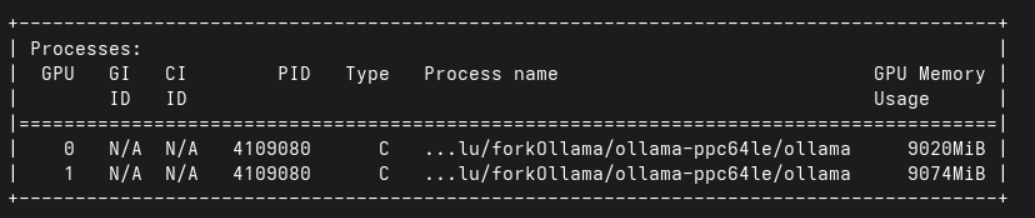
Ollama usando a GPU
Considerações finais
Com os passos apresentados, foi possível configurar o ambiente para executar inferências de LLMs em uma máquina IBM POWER9, utilizando as GPUs NVIDIA Tesla V100. Com essa abordagem, a inferência de modelos possui um ganho de desempenho significativo em relação à execução via CPU. Utilizando o modelo Meta Llama 3.1 8B Instruct como referência, a execução via GPU atingiu uma maior geração de tokens por segundo em relação à execução via CPU.
Vejamos os dados coletados para uma mesma requisição (Me fale todos os números ímpares até 100) com os dois tipos de execução:
| CPU | GPU | |
|---|---|---|
| Taxa de geração de tokens | 0.71 tokens/s | 79.82 tokens/s |
| Duração total | 3m49s | 4.52s |
| Taxa de avaliação do prompt | 10.67 tokens/s | 295.77 tokens/s |
Com os dados apresentados na tabela, percebemos que a execução com GPU foi aproximadamente 112 vezes mais rápida na geração de tokens, com o tempo total de resposta reduzido de 3 minutos e 49 segundos para 4.52 segundos.
Próximos Passos
- Avaliar a execução com GPU e CPU em um post comparativo e com outras arquiteturas;
- Testar a inferência em GPU com modelos maiores, com mais de 8 bilhões de parâmetros, por exemplo;
- Testar novos modelos disponíveis no fork atualizado, como Gemma 3 e DeepSeek;