Avaliação de Modelos IBM Granite para Tarefas de Geração de Código no HumanEvalX
Contexto
O uso de modelos de linguagem para geração e compreensão de código tem se tornado essencial em fluxos de desenvolvimento modernos.
Como parte do esforço conjunto entre o LSD/UFCG e a IBM Brasil, investigamos a performance da família IBM Granite 4 no benchmark HumanEvalX, que avalia capacidades de programação em cinco linguagens: Python, Java, Go, C++, e JavaScript.
O objetivo foi responder perguntas centrais da equipe:
- Quão versáteis são os modelos Granite entre linguagens diferentes?
- Modelos menores entregam performance útil?
- Como os Granite se posicionam frente a modelos open-source como DeepSeek Coder e CodeLlama?
Metodologia / Processo
A avaliação foi conduzida utilizando o OpenCompass, um framework moderno e extensível para benchmarking de LLMs em escala. Ele permitiu executar todos os experimentos de forma padronizada, reprodutível e com protocolos consistentes de inferência.
Como o OpenCompass não possui suporte nativo aos modelos hospedados na IBM Cloud, foi necessário desenvolver um client personalizado para integrar o framework à IBM Cloud Inference API. Esse client permitiu que o processo de avaliação executasse requisições de forma transparente, tratasse autenticação, controlasse parâmetros de geração e retornasse as respostas no formato esperado pelo benchmark. Os experimentos também foram executados no Google Colab, que serviu como ambiente prático de prototipação e execução dos modelos.
Utilizamos o benchmark HumanEvalX, uma extensão do HumanEval tradicional, cobrindo cinco linguagens com métricas consistentes de avaliação como, por exemplo ,Pass@1.
Os modelos avaliados incluíram:
- Granite 4.0 Micro (3B)
- Granite 4.0 (1B)
- Granite 4.0 h-tiny (7B)
- Granite 4.0 h-small (30B) — via IBM Cloud
- granite 4.0 (350M)
- granite code instruct 8B — via IBM Cloud
- DeepSeek Coder (6.7B)
- CodeLlama (7B)
A métrica utilizada foi Pass@1, seguindo o protocolo do benchmark.
Resultados e Conclusões
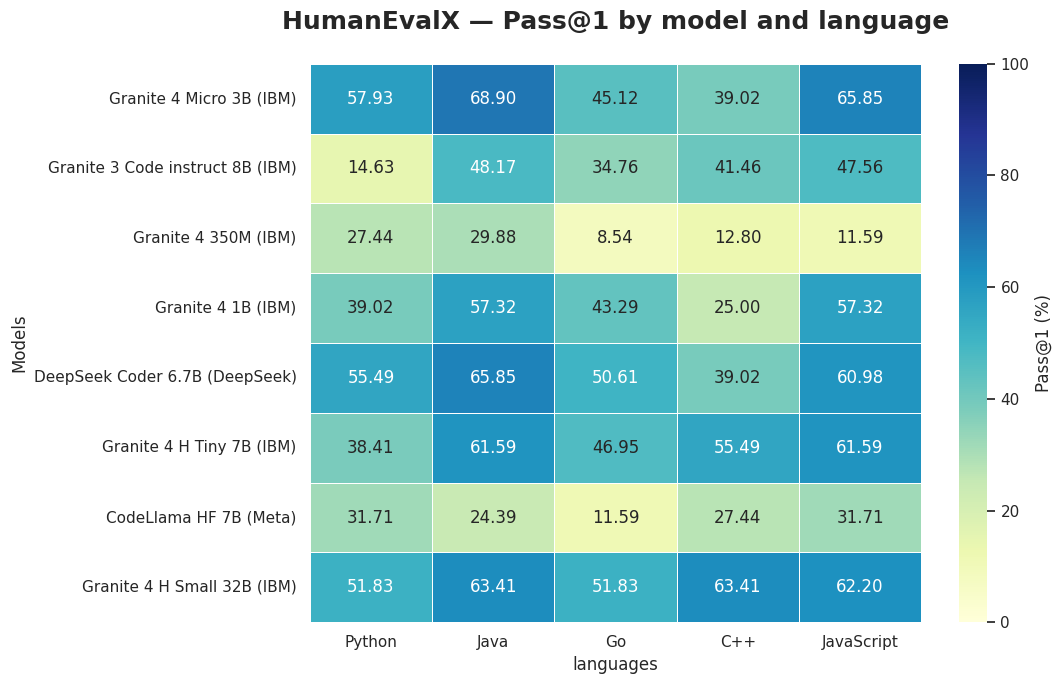
Heatmap do desempenho dos modelos no HumanEvalX.
A avaliação revelou comportamentos importantes:
1. O granite-4.0-h-small se destacou pela versatilidade
Ele superou 60% de Pass@1 em Java, C++ e JavaScript, além de manter mais de 50% em Python e Go. Esse desempenho consistente entre linguagens sugere que o modelo tem boa capacidade de generalização, mostrando-se promissor em cenários que envolvem diferentes ecossistemas de programação, embora análises adicionais em outros benchmarks sejam importantes para uma conclusão mais ampla.
2. O Granite Micro (3B) apresentou performance acima do esperado
Apesar de ser um modelo pequeno, o Granite Micro (3B) surpreendeu ao alcançar 65.85% em JavaScript e 68.90% em Java, superando inclusive modelos maiores avaliados. Esse comportamento mostra que, mesmo com uma arquitetura compacta, ele consegue entregar resultados sólidos, tornando-se uma opção altamente eficiente para aplicações que exigem baixo custo computacional sem abrir mão de desempenho.
3. A progressão de tamanhos (350M → 1B → 3B → 7B → 30B) mostra evolução gradual e coerente
Os resultados mostram que, à medida que avançamos pelos diferentes tamanhos da linha Granite, há uma evolução coerente no desempenho. Os modelos menores entregam resultados estáveis dentro da sua categoria, enquanto os maiores ampliam progressivamente a capacidade de resolver tarefas mais complexas. Essa distribuição ajuda a entender melhor onde cada modelo se encaixa no espectro de uso.
4. A comparação entre provedores ajuda a contextualizar os resultados
Ao lado dos modelos da IBM, também avaliamos modelos de outros provedores, como DeepSeek e Meta. Em algumas linguagens, as diferenças foram pequenas, mas em todas elas houve ao menos um modelo da família Granite que alcançou a melhor pontuação. Os modelos Granite 4 Micro (3B) e Granite 4 h-small (30B) foram os destaques com resultados que ficaram próximos, e em alguns casos acima, de modelos reconhecidos por serem especialistas em código.
Próximos Passos
- Executar os mesmos modelos da família Granite no LiveCodeBench, um benchmark mais amplo que vai além de code-generation, avaliando também code execution e test-output.
- Realizar um fine-tuning de um modelo Granite 4.0 Micro (3B) utilizando o InstructLab e observar o impacto dessa adaptação no desempenho do modelo no HumanEvalX, comparando antes e depois do ajuste.