TensorFlow 2.21 CPU na IBM Power9 (ppc64le)
Contexto
O TensorFlow (TF) é o framework de machine learning mais adotado globalmente. No entanto, desde 2021, o Google encerrou o suporte oficial de binários pré-compilados para a arquitetura ppc64le, e o repositório comunitário tensorflow/community foi arquivado em 2025.
Ambiente utilizado
- Hardware: Arquitetura ppc64le;
- RAM: ~64GB;
- Execução: Máquina Virtual (VM);
- Sistema Operacional: Alma Linux 8.10 (ppc64le), binário compatível com Red Hat Enterprise Linux (RHEL) 8.9/8.10.
Setup Inicial (Instalação do TF 2.14)
Como ponto de partida, validamos a instalação do TensorFlow 2.14.1 (via RocketCE) em uma VM IBM Power9 (arquitetura ppc64le) com AlmaLinux, usando Miniforge (conda). Seguem os comandos para a instalação:
conda create -n tf214 python=3.11 -y
conda activate tf214
conda install -c rocketce tensorflow-cpu=2.14.1 -y
# saída esperada: 2.14.1
python -c "import tensorflow as tf; print(tf.__version__)"
Como resultado, espera-se o TensorFlow 2.14.1 funcional. Essa mesma versão também está disponível nos canais Open-CE da Oregon State University e do MIT. Com o TF 2.14 funcionando, temos acesso ao: Keras, TensorBoard, TensorFlow Hub, tensorflow-text, Hugging Face Transformers, Jupyter, e todo o stack de ML clássico.
TF 2.14 vs TF 2.21 (o mais recente)
A versão 2.14 é funcional, mas está a algumas versões de distância da mais recente, a 2.21. As diferenças mais significativas se concentram na incompatibilidade com duas ferramentas muito importantes:
- Keras 3: uma reescrita completa que transforma o Keras em um framework multi-backend, que permite rodar o mesmo modelo e o mesmo código em TensorFlow, PyTorch ou JAX sem qualquer alteração. O TF 2.14 dá suporte apenas ao Keras 2.
- NumPy 2: Além de corrigir dezenas de inconsistências históricas da API, o NumPy 2.0 traz ganhos significativos de eficiência. O TF 2.14 não suporta o NumPy 2.
Compilando o TensorFlow 2.21 Nativamente no Power9 (CPU-Only)
Inicialmente, compilamos com sucesso o TensorFlow 2.21 (CPU-Only) diretamente a partir do código-fonte. Essa compilação foi realizada em uma VM IBM Power9 e gerou um pacote .whl nativo para linux_ppc64le. Em seguida, o TF 2.21 teve seu funcionamento validado através de uma suíte completa de testes. Este é um marco fundamental sobre o qual o suporte a GPU será construído na próxima etapa.
Desafios: Hermetismo e Dependência de x86
A arquitetura moderna do TensorFlow (e seu sistema de build, o Bazel 7) abraçou o modelo “Hermético”: forçando o uso de binários pré-compilados e lógicas atreladas às arquiteturas x86_64, aarch64 e aceleradores NVIDIA. Para ppc64le, isso significa que a compilação naive simplesmente falha ao tentar baixar ferramentas para arquiteturas incompatíveis.
Identificamos quatro categorias de bloqueio:
- Bazel 7: O Google não distribui o Bazel 7 para PowerPC. Seria necessário compilá-lo do zero.
- Toolchains herméticas: O TF 2.21 tenta baixar LLVM/Clang pré-compilado para x86 ou aarch64, que não executa no Power9.
- Dependências CUDA/GPU: Mesmo em modo CPU-only, o sistema de build tenta baixar e vincular bibliotecas NVIDIA gigantes. Nossa estratégia foi isolar completamente o suporte a GPU com stubs vazios, garantindo uma fundação CPU-only estável antes de adicionar qualquer acelerador.
- Bugs de C++ latentes: O código do XLA e do MLIR contém construções que funcionam no Clang do Google, mas quebram no GCC 8.5 padrão do sistema, de flags AVX-512 até ambiguidades de template em
absl::NoDestructor.
Processo de Compilação
Etapa 1: Compilando o Bazel 7.1.0 do Zero
Como o Google não distribui o Bazel 7 para ppc64le, o primeiro passo para permitir seu uso em arquitetura ppc64le foi compilar o próprio Bazel a partir do seu código-fonte, usando o arquivo -dist.zip, que já inclui os artefatos de bootstrap necessários para que o Bazel se autoconstrua sem depender de uma versão anterior de si mesmo. O processo exige Java 21 e leva entre 1 e 2 horas dependendo dos núcleos disponíveis na VM. O ponto crítico aqui é passar as variáveis corretas para o script compile.sh. Sem esse passo, nenhuma das etapas seguintes é possível. O comando bazel build simplesmente não existe para ppc64le de outra forma. Criamos um tutorial com o processo de instalação do Bazel 7.1 que pode ser acessado no repositório.
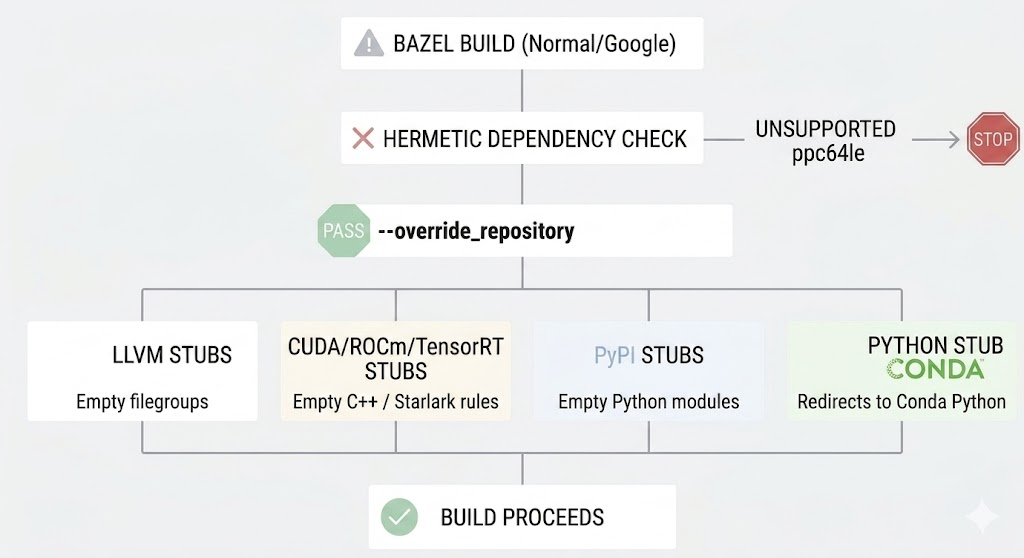
Etapa 2: Estratégia de Bypass — Repositórios Stub
Com o Bazel 7 funcional em arquitetura ppc64le, atacamos o problema das dependências herméticas. Nossa solução foi criar repositórios “stub”, diretórios locais vazios que satisfazem as declarações de dependência do Bazel sem baixar nada:
- LLVM stubs: Filesgroups vazios que satisfazem as regras de toolchain sem tentar instalar o LLVM.
- CUDA/ROCm/TensorRT stubs: Bibliotecas C++ e regras Starlark vazias que permitem que o build prossiga sem erros de dependência faltante.
- PyPI stubs: Módulos Python stub que simulam as dependências do pip hermético do Google, forçando o uso das bibliotecas do ambiente conda.
- Python stub: Redireciona para o Python do nosso ambiente conda, contornando o download do Python hermético que não existe para ppc64le.
Todos os stubs são injetados via --override_repository na chamada do bazel build, sem alterar o código-fonte do TensorFlow.
Estratégia de Bypass - Repositórios Stub
Etapa 3: Patches Cirúrgicos no Código-Fonte
Com a infraestrutura de build resolvida, encontramos 21 incompatibilidades no código C++ e Python do TensorFlow que se manifestam exclusivamente na combinação GCC 13 + ppc64le. Os problemas se concentraram em três categorias:
- Flags de compilação exclusivas do Clang que o GCC rejeita.
- Ambiguidades de templates C++ em componentes do XLA e MLIR que o compilador do Google mascara mas o GCC 13 expõe.
- Referências a headers de CUDA e TensorRT que deixam de existir quando substituídos pelos stubs.
Cada incompatibilidade foi resolvida com um patch Python preciso, sem alterar a lógica funcional do TensorFlow. A tabela completa com todos os 21 patches está disponível no repositório.
Etapa 4: A Compilação
Com todos os patches aplicados, a compilação final é disparada com um único comando bazel build. Além das flags de otimização padrão, o comando injeta todos os repositórios stub via --override_repository, totalizando cerca de 80 flags. O cache incremental do Bazel é fundamental aqui: cada vez que um patch é necessário e a compilação é retomada, apenas os alvos afetados são recompilados. Isso transformou o ciclo “patch → compilar → erro → patch” de inviável em gerenciável (cerca de 4 horas).
A Solução Definitiva: Pacote Conda e Binários (Pronto para Uso)
Para que a comunidade não precise refazer todo esse complexo processo de build, nós empacotamos o resultado dessa engenharia em uma solução “plug and play”.
Disponibilizamos uma Release oficial no repositório contendo o código-fonte já com todos os patches aplicados e o binário .whl gerado nativamente. Mais importante ainda: criamos e publicamos uma receita Conda completa que resolve de forma automática os clássicos problemas de compatibilidade de bibliotecas C++ (GLIBCXX e GCC mismatch) comuns no Power9.
Agora, o TensorFlow 2.21 nativo pode ser instalado diretamente através do nosso canal Conda, proporcionando a mesma experiência de instalação oficial de distribuições corporativas.
Como Instalar (Tutorial Rápido)
Para utilizar o TensorFlow 2.21 em seu ambiente Power9 imediatamente, basta executar:
conda create -n tf221 python=3.11 -y
conda activate tf221
conda install -c ufcg-ibm -c conda-forge tensorflow-cpu=2.21.0 -y
Um tutorial detalhado de instalação via Conda também está disponível no nosso repositório.
Resultado Funcional no servidor IBM Power9
Instalamos o pacote final e executamos uma suíte completa de 35 testes, cobrindo oito categorias funcionais: desde operações básicas com tensores até save/load de modelos e testes de stress. Todos os 35 testes passaram. O teste de stress (multiplicação de matrizes 5000×5000) executou com sucesso na CPU do IBM Power9, e o treinamento de um MLP por 20 épocas confirmou convergência de loss, indicando que diferenciação automática, otimizadores e operações numéricas estão todos funcionando corretamente de ponta a ponta.
Ferramentas IBM que usam TensorFlow
Ferramentas de IA da IBM como AIF360, AIX360 e ART, já eram compatíveis com o TensorFlow 2.14, pois são bibliotecas Python que utilizam o TF do ambiente sem acoplamento binário. O valor real do TensorFlow 2.21 compilado nativamente para Power9 está na continuidade: essas bibliotecas já começavam a declarar dependências em versões de TF superiores ao 2.14, o que significava que, sem esse build, o ambiente no Power9 ficaria preso em versões antigas e sem suporte. Além disso, as melhorias acumuladas no TF entre as versões 2.14 e 2.21 trazem ganhos incrementais de desempenho para os pipelines de análise de fairness, explicabilidade e robustez adversarial.
Reprodutibilidade e Materiais
Todo o processo e os artefatos gerados estão documentados e disponíveis em nosso repositório:
- Release oficial: Código-fonte alterado e o binário
.whlpronto. - tutorial_instalacao_conda.md: Guia prático para instalar a versão 2.21 diretamente pelo nosso canal Conda.
- tutorial_bazel7_power9.md: Compilação do Bazel 7.1.0 a partir do código-fonte.
- tutorial_tf221_power9.md: Compilação do TensorFlow 2.21 com todos os patches.
Impacto
Esta compilação representa a versão mais recente do TensorFlow disponível nativamente para ppc64le e com ela:
- Keras 3 fica disponível para ppc64le pela primeira vez.
- NumPy 2.0 deixa de ser um gargalo para o ecossistema científico Python no IBM Power9.
- Stack Hugging Face Transformers com mais modelos compatíveis com a Power9.
Próximos Passos
O TF 2.21 que compilamos roda exclusivamente em CPU. O próximo desafio é repetir o processo com CUDA habilitado em servidores IBM Power9 equipados com GPUs NVIDIA. Os stubs que criamos para isolar a GPU nesta compilação foram projetados justamente para facilitar essa transição: ao substituí-los pelas bibliotecas CUDA reais, teremos um ponto de partida sólido para a compilação GPU. Se bem-sucedido, o Power9 passaria a ter o framework de deep learning mais recente com aceleração de hardware, algo inexistente hoje em qualquer distribuição para ppc64le.