API de inferência de Modelos de Linguagem no servidor Power9 IBM
Contexto
Este é o quarto e último post de uma série de tutoriais cujo objetivo é mostrar passo a passo como construir uma API de Modelos de Linguagem em um servidor Power9, desde a configuração do sistema operacional até a execução remota de inferências. Já configuramos o sistema operacional, os drivers NVIDIA, CUDA e cuDNN no primeiro post, no segundo post instalamos Conda e PyTorch e no terceiro post construímos a API. Nesta etapa, vamos apresentar a API construída e mostrar como realizar requisições.
TL;DR
- Este post apresenta a API de inferência de LLMs construída e como utilizar.
- Vamos mostrar como realizar requisições via python e curl.
Apresentando a API
Esta API foi desenvolvida para expor modelos de linguagem de grande porte para inferência remota. Permite ao usuário carregar modelos específicos, mantê-los na memória da GPU para chamadas sucessivas e gerar texto a partir de prompts enviados via requisição HTTP. Foi implementada em FastAPI e inclui controle de acesso via API Key, gerenciamento de memória (carregar e descarregar modelos), suporte a múltiplas GPUs com sharding automático e endpoints para consulta de status. O objetivo é oferecer um serviço robusto, otimizado para uso intensivo, garantindo rapidez nas inferências e facilidade de integração com aplicações externas.
Visão Geral da Arquitetura
A API expõe modelos de linguagem via FastAPI com endpoints REST. O ModelManager gerencia o carregamento, descarregamento e a inferência dos modelos, mantendo-os em GPU para chamadas rápidas. A autenticação é feita por API Key. A arquitetura suporta múltiplas GPUs com sharding automático para otimizar o uso de memória e desempenho. Os modelos são importados do HuggingFace e utiliza a biblioteca Transformers para execução de inferências.
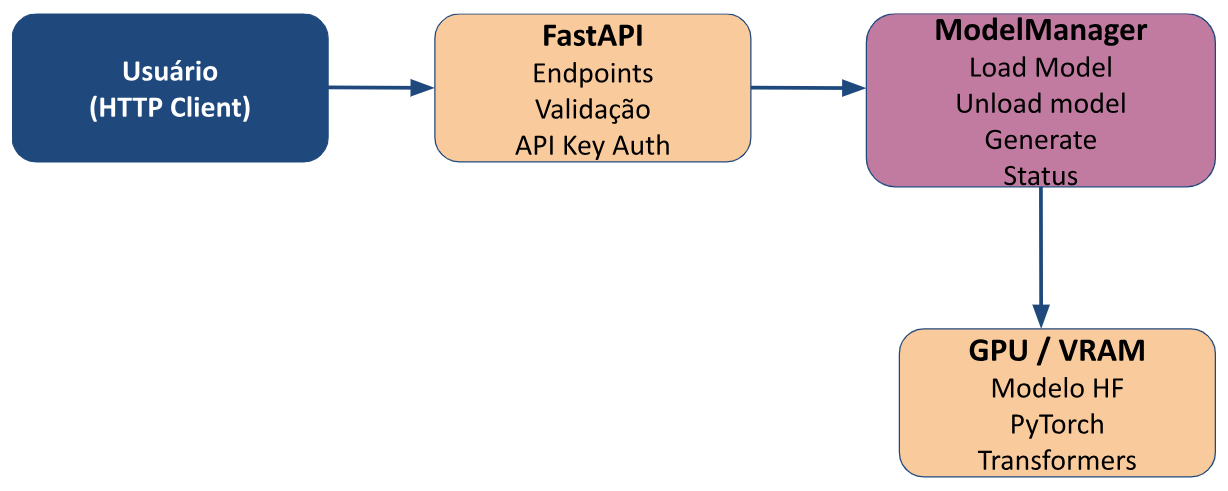
Diagrama da arquitetura
Principais Funcionalidades
Carregar Modelos
/load_model- Carrega modelo do HuggingFace Hub
- Faz sharding para as GPUs
- Suporte ao HuggingFace Token
Gerar Texto
/generate- Recebe prompt, max_tokens, nome do modelo, temperatura e top_p
- Usa modelo já carregado ou carrega um novo
- Retorna resultado em JSON
Gerenciamento
/status: Verifica modelo carregado em device (CPU/GPU)/unload_model: libera GPU e memória/generate_apikey: cria chaves a partir de usuário LDAP
Fluxo de Uso
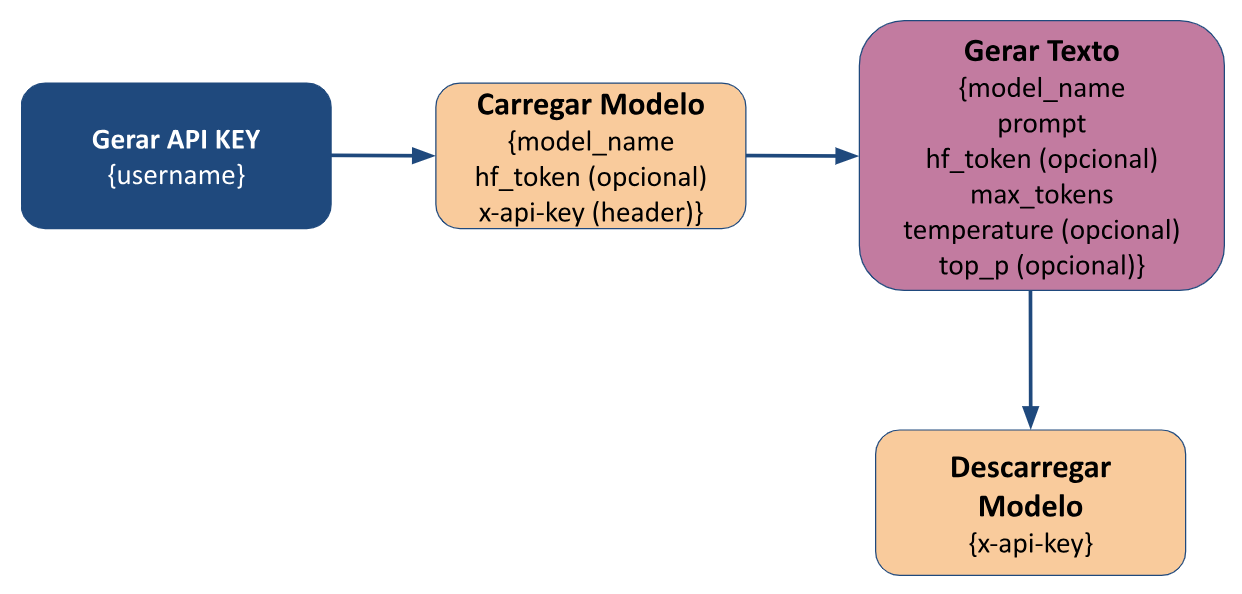
Diagrama do fluxo de uso
Entradas e Endpoints
Na tabela abaixo estão descritos o endpoints da API, entradas necessárias e retornos.
| Endpoints | Método | Api Key | Entrada (Body/Query) | Retorno |
|---|---|---|---|---|
/generate_apikey | POST | ❌ | {username} | API Key |
/load_model | POST | ✅ | {model_name hf_token(opcional) device(opcional)} | Nenhum, apenas carrega o modelo |
/generate | POST | ✅ | {model_name prompt hf_token(opcional) max_tokens(opcional) temperature(opcional) top_p(opcional) } | Texto gerado pelo modelo |
/status | GET | ✅ | Nenhuma | Status do modelo e dispositivo que ele está carregado |
/unload_model | POST | ✅ | Nenhuma | Nenhum, apenas descarrega o modelo |
Como usar a API com Python
Gerar API Key
1import requests
2import json
3import os
4
5url = "http://<ip_servidor_power9>:8000/"
6username = <usuario_ldap>
7hf_token = os.getenv("HUGGINGFACE_TOKEN")
8
9response = requests.post(f"{url}/generate_apikey", json={"username": username}).content.decode()
10
11api_key = json.loads(response).get("api_key")
- É importante que o HuggingFace Token esteja definido como variável de ambiente no local em que esteja executando a inferência.
api_keyserá o retorno da função chamada.
Carregar Modelo
Primeiramente precisamos criar um header que irá conter a API Key retornada com o código acima e o payload que irá conter o model_name o token do huggingface hf_token. Após isso, podemos enviar a requisições com essas duas informações.
1headers = {"Content-Type": "application/json",
2"x-api-key": api_key}
3
4payload = {"model_name": "ibm-granite/granite-3.3-8b-instruct",
5 "hf_token": hf_token}
6
7resp = requests.post(f"{url}/load_model", headers=headers, json=payload)
Gerar Texto
Agora precisamos criar um novo payload com as informações necessárias para gerar um texto com uma llm, são elas: prompt, model_name e hf_token.
1payload = {"prompt": "Olá, me fale um pouco sobre a Universidade Federal de Campina Grande (UFCG)",
2 "model_name": "ibm-granite/granite-3.3-8b-instruct",
3 "hf_token": hf_token}
4
5resp = requests.post(f"{url}/generate", headers=headers, json=payload)
6
7resp = json.loads(resp.content.decode())
Consultar status e descarregar o modelo
Para consultar o status e descarregar o modelo não precisamos passar conteúdo pelo payload, apenas o header com a API key:
1requests.get(f"{url}/status", headers=headers).content
1resp = requests.post(f"{url}/unload_model", headers=headers)
Como usar a API com curl em CLI
Gerar API Key
curl -X POST "http://<ip_servidor_power9>:8000/generate_apikey" \
-H "Content-Type: application/json" \
-d '{"username": <usuario_ldap>}'
- É importante que o HuggingFace Token esteja definido como variável de ambiente no local em que esteja executando a inferência.
- O usuário no campo de
usernamedeve estar entre aspas (" “) - Após executar a requisição acima, a API key retornada deverá ser salva como variável de ambiente para facilitar as próximas execuções. Para salvar você deve copiar a API key retornada e executar o comando:
export API_KEY_P9=<api_key_retornada>
Carregar Modelo
curl -X POST "http://<ip_servidor_power9>:8000/load_model" \
-H "Content-Type: application/json" \
-H "x-api-key: $API_KEY" \
-d '{
"model_name":"ibm-granite/granite-3.3-8b-instruct",
"hf_token":"'"$HUGGINGFACE_TOKEN"'"
}'
Gerar Texto
curl -X POST "http://<ip_servidor_power9>:8000/generate" \
-H "Content-Type: application/json" \
-H "x-api-key: $API_KEY" \
-d '{
"model_name": "ibm-granite/granite-3.3-8b-instruct"
"prompt":"Olá, me fale um pouco sobre a Universidade Federal de Campina Grande (UFCG)",
"hf_token": "'"$HUGGINGFACE_TOKEN"'",
"max_tokens":50
}'
Consultar status e descarregar o modelo
Para consultar o status e descarregar o modelo não precisamos passar conteúdo pelo payload, apenas o header com a API key:
curl -X GET "http://<ip_servidor_power9>:8000/status" \
-H "Content-Type: application/json" \
-H "x-api-key: $API_KEY"
curl -X POST "http://<ip_servidor_power9>:8000/unload_model" \
-H "Content-Type: applicatzion/json" \
-H "x-api-key: $API_KEY"
Esperamos que estes posts tenham ajudado a esclarecer todo o processo de desenvolvimento e implantação. O time LLM-IBM-UFCG está à disposição para dúvidas ou sugestões sobre aprimoramentos futuros.