Inferência de LLMs com vLLM Utilizando GPU em Power9
Contexto
Este post tem como objetivo apresentar os passos necessários para instalar o vLLM em um ambiente IBM POWER9 (arquitetura ppc64le). Serão detalhados os principais recursos necessários, modificações, dependências, versões utilizadas e etapas de instalação necessárias para executar inferências com um determinado modelo.
O vLLM é uma ferramenta voltada para serving e inferência eficiente de modelos de linguagem de grande porte (LLMs), permitindo disponibilizar modelos por meio de uma API e executar inferências de forma otimizada, especialmente em ambientes com GPU.
A necessidade de instalar o vLLM surgiu durante o processo de geração de dados com a ferramenta InstructLab. Nesse fluxo, é necessário utilizar um modelo professor para gerar dados sintéticos que serão posteriormente utilizados no treinamento ou refinamento de outros modelos. Para isso, é possível utilizar ferramentas como llama-cpp, já compatível com o ambiente IBM POWER9, ou o vLLM, que ainda não estava disponível devido a dificuldades relacionadas à instalação nesta arquitetura. Diferentemente do llama-cpp, que é mais voltado para execução local e cenários de menor escala, o vLLM se destaca pelo melhor aproveitamento de GPU e pela capacidade de atender múltiplas requisições simultaneamente de forma eficiente, sendo mais adequado para cenários de inferência em larga escala e ambientes de produção.
Dessa forma, apresentaremos os passos técnicos necessários para viabilizar a instalação do vLLM no ambiente IBM POWER9 (ppc64le), descrevendo as adaptações realizadas para que a ferramenta funcione corretamente nesse contexto.
TL;DR
- Compilação e instalação do LLVM, necessário como infraestrutura de compilação para dependências subsequentes.
- Compilação e adaptação do Triton, incluindo ajustes para compatibilidade com a arquitetura Power9.
- Instalação e configuração do vLLM, considerando suas dependências e requisitos específicos de execução.
- Desenvolvimento de containers contendo todo o ambiente configurado para execução da ferramenta.
- Demonstração prática do uso das imagens, incluindo a inicialização do servidor e a realização de inferências utilizando GPU.
Ambiente de Execução
O ambiente utilizado para a instalação do vLLM inclui:
- Arquitetura: Servidor IBM Power9 (Arquitetura ppc64le).
- Sistema Operacional (SO): AlmaLinux 8.10 binário compatível com Red Hat Enterprise Linux (RHEL) 8.9/8.10.
- RAM: 512GB.
- GPUs: 4x NVIDIA Tesla V100 SXM2 16GB (NVLink2).
Dependências e Instalação
Durante o processo de build do vLLM, destacam-se três dependências principais: LLVM, Triton e PyTorch. Essas dependências são problemáticas para o funcionamento correto da ferramenta.
O LLVM constitui a base da infraestrutura de compilação utilizada ao longo de todo o processo, sendo responsável pela geração, otimização e transformação de código intermediário em código de baixo nível executável. No contexto do vLLM, sua função é essencial para viabilizar a execução eficiente de kernels em GPU, especialmente aqueles definidos pelo Triton, que dependem diretamente de seus backends de compilação (componentes responsáveis por gerar código otimizado para diferentes arquiteturas de hardware). O Triton, por sua vez, atua como o componente responsável pela definição e execução de kernels otimizados para GPU, desempenhando um papel central na eficiência da inferência de modelos de linguagem. Sua integração com o LLVM permite a geração de código altamente otimizado para diferentes arquiteturas. Já o PyTorch fornece a base para a manipulação de tensores e execução dos modelos de linguagem, oferecendo as operações fundamentais para inferência em GPU, além de servir como interface com os mecanismos de aceleração e bibliotecas de baixo nível.
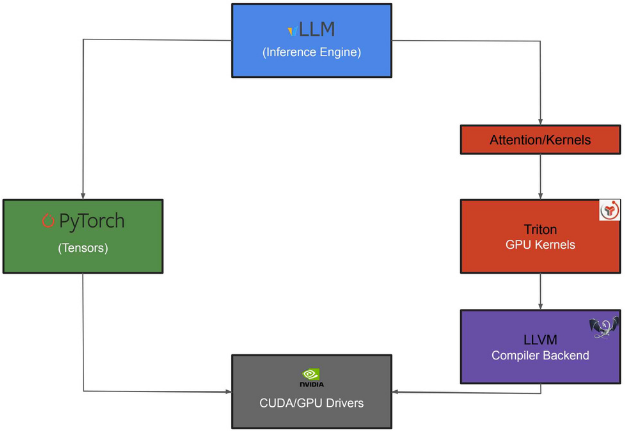
Fluxo de Dependências para compilar vLLM na Power9.
Devido à ausência de suporte nativo desses pacotes para a arquitetura ppc64le, sua utilização na IBM POWER9 exigiu a realização de diversas adaptações a partir dos repositórios oficiais dessas ferramentas. Essas modificações envolveram desde a correção de incompatibilidades em métodos específicos até ajustes em subdependências que não possuíam suporte para a arquitetura ppc64le, além do uso do Conda para auxiliar na gestão de ambientes e dependências. Em alguns casos, também foi necessária a compilação manual de componentes adicionais. Após a superação desses desafios, tornou-se possível instalar e executar o vLLM no ambiente IBM POWER9.
Devido à grande quantidade de etapas envolvidas, o passo a passo com os procedimentos detalhados são apresentados neste link: guia-instalacao-vllm. Ressalta-se que cada um dos passos descritos é essencial para garantir a correta compilação e execução do vLLM no ambiente proposto.
Conteinerização
Durante o processo de instalação, observou-se que a grande quantidade de etapas envolvidas poderia dificultar a reprodução do ambiente e levar à cenários inconsistentes. Diante disso, optamos pela conteinerização da solução como forma de tornar o experimento reprodutível, portátil e mais simples de ser utilizado por outros usuários. Para isso, disponibilizamos (neste repositório) scripts responsáveis tanto pela construção das imagens quanto pela automação da execução, organizando todas as etapas necessárias. Esses scripts realizam tarefas como a identificação dos recursos disponíveis, cópia dos binários CUDA necessários e a inicialização do vLLM de forma adequada.
A execução foi simplificada de forma que é necessário que o usuário apenas informe o caminho local do modelo a ser utilizado. Parâmetros como porta, quantidade de GPUs e imagem a ser executada são opcionais, possuindo valores padrões previamente definidos.
Repositório desenvolvido para execução do vLLM via containers.
Além disso, disponibilizamos um vídeo (demonstração do vLLM no Power9) que demonstra o uso do vLLM a partir do repositório disponibilizado.
Considerações Finais
Com os recursos disponibilizados neste repositório, tornou-se possível automatizar o processo de instalação e utilização do vLLM em arquiteturas ppc64le com GPUs V100.
No contexto do projeto IBM-MultiArq, essa solução se mostra especialmente relevante para a utilização do InstructLab, permitindo a execução local de modelos professores por meio do vLLM, ampliando as possibilidades de experimentação e desenvolvimento dentro do ambiente proposto.
Próximos Passos
Como continuidade deste trabalho, propõe-se a realização de um estudo comparativo de desempenho entre o llama-cpp e o vLLM. Além disso, o repositório foi estruturado para oferecer suporte contínuo ao vLLM, incluindo sua adaptação a versões futuras, a identificação de limitações ainda existentes e a evolução das soluções à medida que novos desafios surgirem.